L'Errore Minimo di ogni classificatore: Bayes Error Rate
L’errore di Bayes è una di quelle cose che oltre a suonare bene è anche piuttosto interessante: ci indica infatti un confine teorico oltre il quale non possiamo andare.
E questo perché ci mette di fronte non tanto ad un limite tecnico di per sé, ma ad un limite intrenseco del problema stesso, al meglio che si possa ottenere rispetto alla natura stessa del problema da un punto di vista matematico e probabilistico.
Insomma, non se ne scappa.
Un esempio per capire meglio
Immaginiamo un problema di classificazione in cui abbiamo:
- X = [x1, ..., xn] n caratteristiche (feature)
- k classi possibili
A livello teorico, se noi conoscessimo perfettamente come si distribuiscono le caratteristiche X in relazione alle classi y, cioè se conoscessimo P(X | y) — dunque la probabilità di osservare un certo insieme di feature dato che appartiene alla classe y — le probabilità a priori P(y) di ciascuna classe e la probabilità complessiva P(X) di osservare quelle caratteristiche a prescindere dalla classe, allora potremmo usare il teorema di Bayes per calcolare la probabilità a posteriori P(y | X):
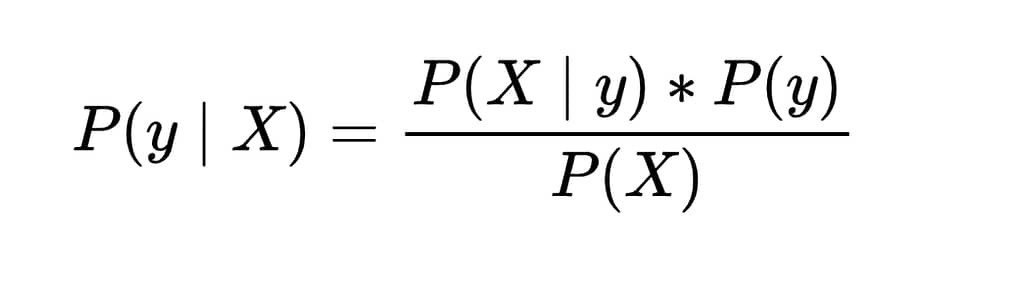
Questo ci direbbe quanto è probabile che un oggetto appartenga alla classe y dato che ha quelle caratteristiche X. Il che ci permetterebbe di classificare sempre in modo ottimale scegliendo la classe con la probabilità a posteriori più alta.
Ora, poichè ci troviamo di fronte a delle distribuzioni di probablità, scegliere la classe con la probabilità più alta ci assicura di classificare correttamente la maggior parte delle volte, ma ci lascia comunque un margine di errore.
In quanto appena detto c'è un dettaglio che può passare inosservato a primo acchitto ma è fondamentale: se anche conoscendo esattamente la distribuzione di probablità di un dato fenomeno io ho comunque un margine di errore, significa che questo errore è imprescindibile, fissato dalla struttura stessa del problema.
Questo margine di errore minimo teorico viene chiamato Bayes Error Rate e rappresenta il tasso di errore più basso che si può ottenere anche con un classificatore perfetto che conosce alla perfezione le leggi probabilistiche che governano il fenomeno e, senza entrare nel dettaglio, un concetto analogo (ma non identico) vale nei problemi di regressione, dove si parla invece di Bayes risk.
In altre parole, questo non è un errore dovuto a un modello sbagliato o a un algoritmo poco sofisticato: è un errore inevitabile, determinato dal fatto che le distribuzioni delle caratteristiche delle diverse classi possono sovrapporsi.
Cosa vuol dire calcolare la probabilità a posteriori P(y | X)?
Poco fa abbiamo parlato di calcolare la probabilità a posteriori P(y | X). Ma cosa signifia?
Facciamo un esempio pratico. Immaginiamo di avere un problema di classificazione con:
- due classi qualunque y = [A, B]
- un certo numero di caratteristiche X = [x₁, ..., xₙ]
e di chiederci quale sia la probabilità che y sia uguale ad A sapendo che abbaimo "misurato" le caratteristiche X = [x₁, ..., xₙ]
In matematichese possiamo scrivere P( A | X )
Questo rappresenta la probablità che, data la misurazione delle caratteristiche X, ci troviamo di fronte ad un oggetto di classe A e tiene conto sia della probabilità che si misurino prorpio quelle caratteristiche avendo un oggetto di classe A, sia della probabilità a priori di avere un elemento di classe A e sia della probabilità di misurare X.
Ma allora, se c'è una certa probabilità di trovarci di fronte ad un oggetto di classe A, viene da sé che c'è anche la probabilità di trovarci di fronte ad un oggetto di classe B e questo discorso, chiaramente, non vale solo per due calssi, ma si generalizza per n classi.
La possibilità di errore è parte del problema stesso
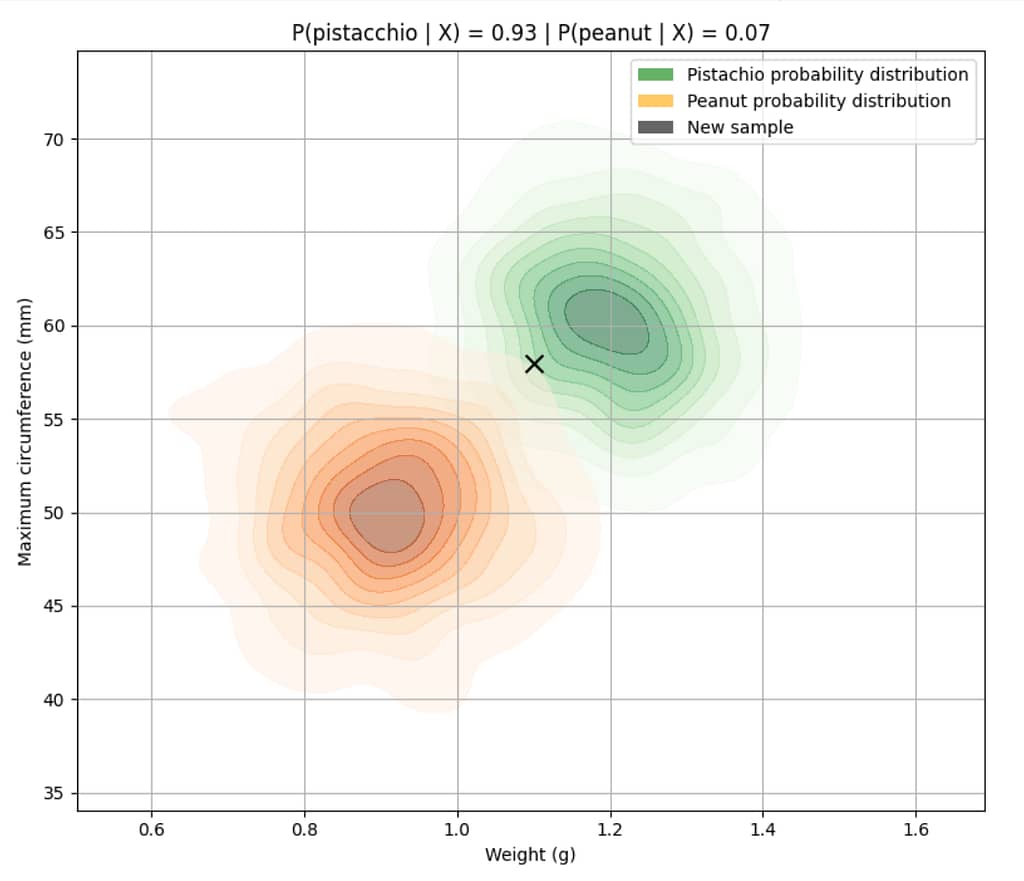
Per capire meglio questo concetto, lasciamo stare A, B e X parliamo di noccioline e pistacchi.
Immaginiamo di avere un dataset con delle misure reali di noccioline e pistacchi, e immaginamo per ognuno di essi conosciamo il peso (g) e la sua massima circonferenza (mm).
Supponiamo inoltre di conoscere perfettamente come si distribuiscono le caratteristiche [peso, massima circonferenza] in relazione alle classi [pistacchio, nocciolina]
Ora ci arriva un nuovo campione con queste misure:
- peso: 1.1 g
- massima circonferenza: 56 mm
👉 La domanda che ci poniamo è: qual è la probabilità che questo oggetto sia un pistacchio, dato che ha le caratteristiche che abbiamo misurato?
Poiché stiamo supponendo di conoscere perfettamente come si distribuiscono le caratteristiche X in relazione alle classi y, per rispondere a questa domanda non dobbiamo fare altro che calcolare la probabiltà che un oggetto sia un pistacchio dato che ha quelle caratteristiche e confrontarla con la probabilità che l'oggetto sia una nocciolina dato che ha quelle caratteristiche.
In pratica calcoliamo P( pistacchio | [1.1, 56] ) e P( nocciolina | [1.1, 56] ) e scegliamo la classe con la probabilità maggiore.
Questo si chiama classificatore di Bayes (o classificatore bayesiano ottimo) ed è il classificatore con l'errore più basso che possiamo avere.
Ma allora a che ci serve il Machine Learning?
Ma quindi, se ci basta utilizzare un classificatore perfetto di Bayes, a cosa ci serve il Machine Learning?
Il punto cruciale è proprio questo: il classificatore di Bayes è un concetto puramente teorico. Funziona perfettamente solo se conosciamo già tutte le distribuzioni di probabilità reali del problema.
Ma nella pratica, nel mondo reale e per problemi reali, non abbiamo mai accesso a queste distribuzioni. Sono nascoste nella complessità della realtà e nei meccanismi che generano i nostri dati.
E non possiamo stimarle?
In teoria sì. In teoria potremmo tentare di stimare direttamente queste distribuzioni raccogliendo una quantità enorme di dati reali e osservando empiricamente come si distribuiscono le caratteristiche in relazione alle classi, in modo puramente frequentista.
Tuttavia, nella pratica questo approccio diventa subito impraticabile.
Questo approccio "frequentista" infatti si basa sulla capacità di stimare le distribuzioni di probabilità sottostanti, partendo da un sottoinsieme delle caratteristiche (quello misurato).
Ora finché abbiamo a che fare con una, due o anche tre caratteristiche, potrebbero bastare un centinaio di esempi per avere delle stime utilizzabili. Ma all’aumentare del numero di caratteristiche, la dimensione del campione necessaria per coprire adeguatamente lo spazio delle possibili configurazioni cresce in modo esplosivo.
Questo fenomeno è noto come curse of dimensionality (e tocca direttamente anche i modelli di Machine Learning) significa che, in spazi ad alta dimensione (cioè con molte feature), i dati diventano inevitabilmente sparsi e la maggior parte dello spazio rimane priva di osservazioni reali, così al crescere del numero di dimensioni.
Di conseguenza, al crescere del numero di dimensioni (caratteristiche) lo spazio diventa sempre più vuoto e i dati risultano via via più rarefatti, dunque abbiamo bisogno di un numero di caratteristiche sempre maggiore per stimare accuratamente le distribuzioni necessarie per applicare direttamente il classificatore di Bayes e questo, ad un certo punto, diventa semplicemente impraticabile.
Ma nelle applicazioni reali, le caratteristiche possono essere decine, centinaia, migliaia o anche di più. E no, non possiamo semplicemente utilizzare meno caratteristiche, perché per fenomeni reali, estremamente non lineari e complessi, abbiamo bisogno di molte features per essere in grado mappare la complessità del fenomeno.
Ed è qui che entra davvero in gioco il Machine Learning
A conti fatti, quello che facciamo quando addestriamo un modello di Machine Learning "non è altro" che cercare di approssimare queste relazioni probabilistiche — senza doverle stimare esplicitamente in modo pienamente frequentista.
In altre parole, non cerchiamo più di calcolare direttamente la distribuzione completa di probabilità di ogni combinazione possibile delle caratteristiche, perché questo richiederebbe quantità di dati astronomiche. Preferiamo invece costruire un modello che, a partire dai dati osservati, impari una rappresentazione compatta e generalizzabile di come le caratteristiche sono legate alle classi.
Così possiamo avvicinarci, per quanto ci è possibile, al comportamento del classificatore di Bayes, pur senza conoscere le vere distribuzioni sottostanti.
Un modello di Machine Learning in pratica — che sia un semplice classificatore lineare, una random forest o una rete neurale — ha proprio il compito di imparare a stimare questa distribuzione, o meglio, di avvicinarsi il più possibile a quella vera, nascosta nei dati.
Questo significa che, idealmente, vorremmo trovare quei parametri θ tali che, dato un nuovo elemento con caratteristiche X, la probabilità stimata per la classe corretta sia maggiore di quella per qualsiasi altra classe
O più formalmente, se Yi è la classe corretta, vogliamo che:
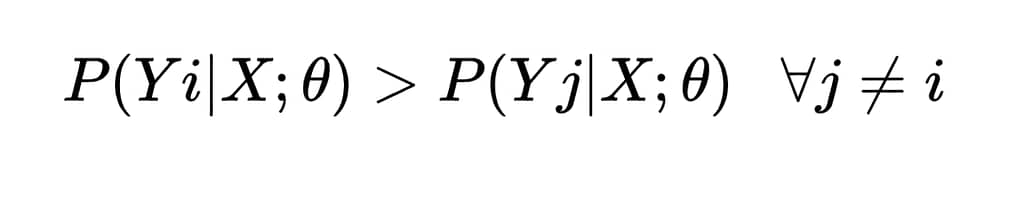
Nella pratica però, proprio perché non conosciamo mai le reali distribuzioni di probabilità sottostanti, il modello non garantisce questa disuguaglianza per ogni singolo esempio, ma ottimizza θ per minimizzare la perdita complessiva sul dataset, riducendo al minimo la frequenza con cui questa condizione viene violata. Un processo che mira ad avvicinarsi, per quanto possibile, al limite teorico stabilito dall’errore minimo di Bayes.
Nota che quanto appena detto non è vero per tutti i modelli, ma solo per i i cosiddetti modelli probabilistici discriminativi (come la regressione logistica o le reti neurali con softmax) cioè quelli che stimano esplicitamente la probabilità a posteriori P( y ∣ X ; θ). In questi casi, l’obiettivo dell’addestramento è proprio quello di imparare una buona approssimazione di queste probabilità e poi decidere in base a quella più alta.
Tuttavia, esistono anche modelli che non stimano direttamente le probabilità, come gli SVM, gli alberi decisionali, o altri modelli discriminativi non probabilistici. Questi modelli non ragionano in termini di P(y | X), ma costruiscono direttamente una regola decisionale, ad esempio una frontiera che separa le classi, ottimizzando un criterio diverso, come il margine massimo o l’impurezza.
Ma anche se il loro approccio è diverso, questi modelli mirano comunque a ridurre l’errore di classificazione, e quindi — almeno in linea teorica — ad avvicinarsi al limite inferiore fissato dall’errore di Bayes, che rimane valido per qualunque modello: proprio perché è un confine dettato dalla natura del problema, non dallo strumento usato.
Il Machine Learning nasce proprio dalla necessità pratica di avvicinarci, con i dati e gli algoritmi a disposizione, al limite teorico stabilito da Bayes: quel confine matematico che rappresenta il miglior risultato possibile dato un certo problema.
Addestrare un modello significa proprio questo: trovare un modo efficiente di rappresentare la complessa relazione probabilistica tra caratteristiche e target, senza dover osservare esplicitamente tutti i casi possibili (cosa che richiederebbe quantità di dati fuori scala).
Ed è bellissimo perché ci riconnette al concetto iniziale: anche con un modello perfetto, l’errore minimo che potremo mai ottenere è fissato dalla struttura intrinseca del problema, dall’inevitabile sovrapporsi delle distribuzioni reali.