
Deep Learning e Neural Networks
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
Nei capitoli precedenti abbiamo parlato di Intelligenza Artificiale e siamo poi entrati un po’ più nel dettaglio parlando di Machine Learning.
Poi abbiamo parlato delle tre categorie di Machine Learning che abbiamo definito come:
- Apprendimento Supervisionato (o Supervised Learning)
- Apprendimento Non Supervisionato (o Unsupervised Learning)
- Reinforcement Learning
Infine nelle ultime tre lezioni abbiamo analizzato queste tre categorie e ne abbiamo visto alcuni usi pratici.
A questo punto siamo pronti a parlare di Reti Neurali e Deep Learning.
Ovviamente qui le cose si fanno tecniche, ma come sempre noi faremo in modo di semplificare tutto e di portarci a casa solo quello che ci interessa.
Cosa è il Deep Learning?

Iniziamo dicendo che non cercheremo di definire la differenza tra il Deep Learning e il Machine Learning, perché nella pratica non ha senso farlo.
Il Deep Learning è un'area del Machine Learning e volerne definire la differenza sarebbe come voler trovare la differenza tra un ananas e la frutta.
Un ananas è un tipo di frutta proprio come il Deep Learning è un tipo di Machine learning. È detta male, ma rende l'idea.
Quando utilizziamo il Machine Learning non necessariamente stiamo utilizzando il Deep Learning, proprio come quando mangiamo un frutto non necessariamente stiamo mangiando un ananas.
Se però utilizziamo in Deep Learning allora stiamo utilizzando il Machine Learning, proprio come quando mangiamo un ananas allora stiamo mangiando un frutto.
Easy peasy lemon squeezy (per restare in tema frutta)
E già che ci siamo, rimanendo sulla similitudine della frutta allora possiamo dire che se il Machine Learning rappresenta la frutta e il Deep Learning rappresenta l’ananas, allora l'Intelligenza Artificiale rappresenta il cibo.
A dirla tutta, in realtà, nei post precedenti di questa serie abbiamo già incontrato alcuni esempi di Deep Learning, e l'abbiamo fatto proprio per semplificarci la vita. Negli esempi fatti nei capitoli precedenti infatti, abbiamo più volte sfruttato il potere del Deep Learning.
Riprendiamo l'esempio del nostro modello che riconosce cani o gatti.
Ecco, abbiamo detto che il modello è in grado da solo di riconoscere strutture e pattern che sono alla base della differenza che contraddistingue cani e gatti.
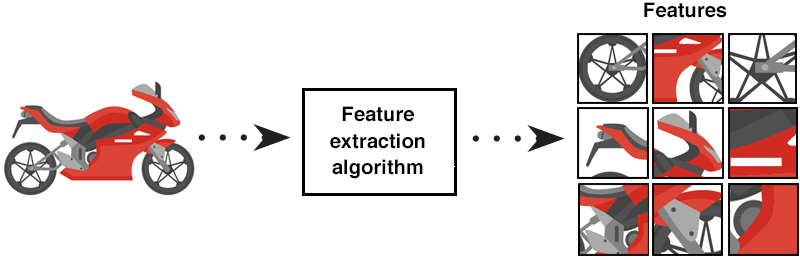
Questa capacità del modello di riconoscere da solo questi elementi attraverso un processo che chiamiamo Features Extraction, è dato proprio dal utilizzo del Deep Learning.
Come avevamo accennato qualche lezione fa infatti, quando abbiamo parlato per la prima volta del Machine Learning e della fase di training, diciamo che senza Deep Learning avremmo dovuto dare una piccola mano al nostro modello durante questa fase.
Non gli avremmo dovuto dare noi le indicazioni esatte che, come abbiamo visto nel capitolo sulla programmazione classica, non conosciamo, ma avremmo dovuto comunque aiutarlo fornendogli quelle che potremmo impropriamente definire “linee guida”.
In pratica, nella fase di training, all'interno del dataset, oltre alle immagini e alle etichette che dicono se nell'immagine è presente un cane oppure un gatto, avremmo dovuto occuparci di passare al modello alcune indicazioni che lo avrebbero aiutato a capire come giungere alla soluzione del problema.
Ad esempio, nelle immagini di cani e gatti gli avremmo potuto evidenziare tramite punti e coordinate all'interno dell'immagine, la sagoma dell'animale rispetto al resto dell'immagine.
Insomma, lo avremmo guidato a individuare gli angoli, gli spigoli e le curve che contraddistinguono un cane da un gatto.
Quali indicazioni fornire dipende molto dal problema specifico e al grado di affidabilità voluto.
Ovviamente questo processo, aumenta di molto il lavoro umano necessario e rende il sistema un po' meno intelligente.

Il Deep Learning invece permette alla macchina di estrarre in maniera autonoma queste caratteristiche (in pratica rende il sistema in grado di compiere in autonomia la fase di Feature Extraction).
Con il Deep Learning quindi, noi non dobbiamo fornire nessuna guida (se non l'etichetta) sul come risolvere il problema ma, semplicemente lasciamo che la macchina ci arrivi da sola.
Esattamente quello che disse il buon Arthur Samuel nel 1949.
Adesso cercheremo di capire a livello concettuale, come fa il Deep Learning a permettere al sistema di individuare in autonomia queste caratteristiche.
Iniziamo dicendo che il Deep Learning è quella branca del Machine Learning (e quindi dell'Intelligenza Artificiale) che imita il modo in cui gli esseri umani risolvono i problemi, andando a simulare la struttura e le funzioni di un cervello umano, imitando il modo in cui i neuroni biologici si scambiano le informazioni.
Come sempre, evitiamo ogni tecnicismo, teniamo le cose semplici e prendiamo la conoscenza che ci serve per i nostri scopi.
Nella definizione di Deep Learning che abbiamo appena dato, abbiamo parlato di neuroni, ma cosa c'entrano i neuroni con il Deep Learning?
Adesso faccio un’affermazione che inizialmente non capiremo, ma che tra pochi minuti sarà più che chiara: diciamo che il Deep Learning non è altro che una Rete Neurale composta da 3 o più strati.
Ma ora facciamo chiarezza e capiamo cosa sono gli strati e cosa è una Rete Neurale.
Un po’ di storia

Tutto nasce nel 1943 quando Warren MCCulloch (neurofisiologo e cibernetico) e Walter Pitts (logico matematico attivo nel campo delle neuroscienze computazionali), si uniscono in team con lo scopo di sviluppare un modello matematico di un neurone.
Il loro lavoro ruotava intorno al fatto che per via del carattere proprio delle attività nervose, degli eventi neurali e delle relazioni tra i neuroni stessi, questi potevano essere trattati mediante la logica proposizionale.
Ora, qui non è necessario capire a fondo questo concetto, quello che ci serve sapere è che nel 1943 un neurofisiologo e un logico matematico hanno unito le loro conoscenze e competenze per riuscire a creare un modello matematico di un neurone.

Successivamente, un altro pioniere di questa disciplina, Frank Rosenblatt, psicologo americano molto attivo nel campo dell'intelligenza artificiale, tanto che da alcuni viene definito come il padre del Deep Learning, riprende e sviluppa ulteriormente gli studi di MCCulloch e Pitts, per dare a questo neurone artificiale la capacità di apprendere, ma soprattutto, lavora alla costruzione del primo dispositivo elettronico che utilizza questi principi: il Mark I Perceptron.
Ma torniamo per un attimo al nostro neurone artificiale. Come per un cervello umano o animale in generale, un solo neurone ha poco potere computazionale. Per ottenere qualcosa di utile dunque, dobbiamo costruire una struttura un po' più complessa composta da strati di neuroni collegati tra di loro. Definiamo questa struttura una Rete Neurale.
Fatta questa definizione importante, torniamo a Frank Rosenblatt che nel 1958 (4 anni dopo la morte di Alan Turing, per fissare delle date di riferimento nel settore) inventa il Mark I Perceptron, il primo vero dispositivo che implementa i concetti di neuroni artificiali, iniziati a essere studiati nel 1943 da MCCulloch e Pitts.
Ecco che successivamente all'invenzione di Rosenblatt, alcuni studiosi del campo dell'Intelligenza Artificiale, tra cui un importante professore dell’MIT, pubblicano un libro, intitolato Perceptron che parla proprio dell'invenzione di Rosenblatt.
In questo libro vengono mostrate due cose.
La prima è come una Rete Neurale, composta da un solo strato di questi neuroni artificiali, non fosse in grado di risolvere problemi matematici molto semplici che ogni calcolatore di allora poteva invece risolvere molto facilmente
Ma la seconda è che dispositivi composti da una Rete Neurale più complessa, fatta da più strati interconnessi tra di loro fossero in grado di risolvere i problemi estremamente complessi.
Universal Approximation Theorem
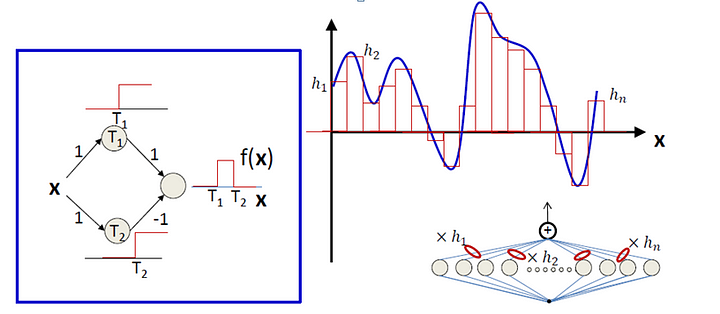
E non è tutto.
Infatti, se prendiamo una rete neurale e la trattiamo come una funzione matematica (e possiamo farlo grazie agli studi di MCCulloch e Pitts), viene fuori che questa funzione è estremamente flessibile.
Anzi, un teorema matematico chiamato Universal Approximation Theorem, mostra che questa funzione, sulla carta, possa risolvere qualunque problema a un qualunque livello di accuratezza, a patto che la Rete Neurale sia composta in maniera appropriata.
E lo ripeto ancora una volta perché è estremamente importante:
un teorema matematico ha mostrato che, sulla carta, una rete neurale, costituita da un numero sufficientemente alto di strati opportunamente interconnessi, è in grado di risolvere qualunque problema a un qualunque livello di accuratezza.
In pratica, mettendo assieme quello che abbiamo detto fino a ora sappiamo che:
- una Rete Neurale composta da un solo strato non è molto utile e non è in grado nemmeno di risolvere problemi tendenzialmente semplici
- una Rete Neurale composta da più strati supera il limite del punto 1 e ci permette di risolvere problemi estremamente complessi
- lo Universal Approximation Theorem ha mostrato che, sulla carta, una Rete Neurale con un numero sufficientemente alto di strati e costituita in modo adeguato, è in grado di risolvere qualunque problema con un qualunque livello di approssimazione
E se ci pensiamo un attimo, alla fine è tutto abbastanza intuitivo.
Abbiamo visto infatti che una Rete Neurale non è altro che un insieme di neuroni artificiali organizzati in strati e abbiamo visto anche che un neurone artificiale non è altro che una rappresentazione matematica di un neurone reale a tutti gli effetti.
Quindi, in pratica, quello che abbiamo appena detto, si riduce nel dire che un sistema di neuroni composto da un solo strato di neuroni non è poi così intelligente ma che, aumentando il numero di strati neuronali, otteniamo un sistema via via sempre più in grado di risolvere problemi complessi.
Make sense!
A questo punto, sappiamo che cos'è una Rete Neurale e conosciamo i suoi limiti e le sue potenzialità. Abbiamo capito inoltre che aumentando il numero di strati della rete, aumenta la potenza computazionale della nostra rete.
Deep Learning
Ora possiamo quindi tornare a parlare di Deep Learning riprendendo la definizione data a poco tempo fa.
Se ricordi infatti, poco fa abbiamo definito il Deep Learning come niente più e niente meno che una Rete Neurale composta da 3 o più strati.

E adesso sappiamo cosa significa! Visto? Te l’avevo detto che era facile!
A questo punto, approfondire cosa sono effettivamente questi strati e perché aggiungere strati aumenta la capacità della rete, ha poco senso per i nostri scopi, ma quello che ci serve sapere è che aggiungere un solo strato in più alla rete aumenta esponenzialmente la capacità della rete stessa.
Quindi una rete a tre strati non è un pochino più potente di una rete a due strati ma lo è molto di più.
Allo stesso modo, una rete a 10 strati è estremamente più potente di una rete a tre strati.
Dunque aggiungere un solo strato a una Rete Neurale aumenta in maniera esponenziale la capacità della rete di risolvere i problemi, allo stesso modo in cui il cervello di un cane è computazionalmente più potente del cervello di un acaro (nulla togliere agli acari, eh).
Ma alla luce di tutto quello che abbiamo detto, qualcuno ora potrebbe chiedersi come mai, se abbiamo capito tutte queste cose già a cominciare dal 1943, non abbiamo ancora i robot laureati in chirurgia!
Diciamo che il concetto è che, come sempre, la teoria è una cosa e la pratica è un'altra.
Abbiamo visto infatti che, per avere qualcosa di utile ai fini pratici e risolvere problemi sempre più complessi, abbiamo bisogno di aggiungere strati alla Rete Neurale.
Ma aggiungere strati non è qualcosa che si fa gratis e con troppa facilità.
Più potere computazionale vuol dire più risorse necessarie, fase di training più complesse e necessità di hardware più performante.
Il progresso che stiamo vivendo negli ultimi 10 anni con la nanotecnologia e la capacità di progettare dispositivi sempre più piccoli con una potenza sempre maggiore, ci sta portando sempre più a sviluppare reti sempre più grandi e più strutturate, in modo da poter tirare fuori il massimo da questa tecnologia.
Basti pensare, per rendere l'idea, che oggi la potenza di calcolo che c'è nei telefonini che abbiamo in tasca è milioni di volte maggiore di quella che aveva l'Apollo 11 che ha portato l'uomo sulla Luna!
Solo 30 anni fa, un dispositivo che ha le capacità dei nostri attuali smartphone, avrebbe richiesto un intero palazzo per essere costruito, ma oggi abbiamo la tecnologia per farcelo stare in tasca.
E sia chiaro: per trainare una Rete Neurale con molti strati su un dataset "pesante", il telefono migliore che abbiamo in tasca non basta.
Abbiamo bisogno di macchine dedicate con una tecnologia hardware di alto livello per ottenere risultati con dei tempi utili nella pratica.
Ma l'accessibilità di questa tecnologia si fa sempre più possibile e gli hardware sempre meno costosi.
E non è solo una questione di disponibilità dell'hardware, è anche una questione di dati.
Come abbiamo visto infatti, trainare una rete per determinati tipi di lavoro, richiede dataset ben strutturati, con una buona quantità di dati di qualità.
La qualità di quello che siamo in grado di produrre infatti è proporzionale alla qualità dei dati che utilizziamo.
Non servono solo tanti dati, ma è anche importante che questi dati siano di qualità.
Ed è proprio grazie al fatto che questa tecnologia adesso si sta diffondendo sempre di più e che l'hardware la stia rendendo sempre più fattibile, che nelle università la si comincia a studiare e che stanno nascendo moltissimi framework e servizi host che la stanno rendendo sempre più accessibile, non solo a pochi eletti e alle grandi multinazionali, ma a chiunque voglia studiare la logica.
Tutto questo sta facendo si che sempre più dataset di qualità stanno nascendo, sviluppati da università, aziende e comunità Open Source e vengono resi disponibili e pronti per essere scaricati e utilizzati
Ad oggi si trovano in rete file di centinaia di GB già etichettati, confezionati e pronto all'uso. E molti di loro si possono utilizzare gratis.
30 anni fa, l’accesso a questa mole di informazioni era inimmaginabile ma oggi grazie a internet è realtà concreta.
Non per niente spesso si sente dire “data is the new gold”.
Tutto questo ci sta permettendo di spostare sempre più avanti la nostra conoscenza in questo campo, permettendoci di costruire architetture di Reti Neurali sempre più adatte e perfezionate alla risoluzione di problemi specifici, o di creare reti neurali sempre più grandi e sempre più complesse.
Tutto questo apre le porte a un futuro che va molto oltre quello che oggi siamo in grado di immaginare proprio come internet negli anni 90 ha aperto le porte a un futuro che a quel tempo faticavamo a prevedere con chiarezza.







