
Elementi di Machine Learning
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
In questa capitolo parleremo di Machine Learning.
Sebbene il nome possa fare un po’ paura a chi non è tecnico e possa sembrare un argomento molto complicato, in realtà, a livello concettuale è tutto molto semplice, soprattutto sei hai letto con attenzione i precedenti post di questa serie.
Ovviamente, essendo questa una guida non tecnica all'Intelligenza Artificiale, non entreremo in dettagli che non ci serve sapere (se però ti interessa approfondire, trovi molti post più tecnici sul mio blog) e soprattutto, come sempre tratteremo l'argomento facendo in modo di tenere tutto il più semplice e intuitivo possibile, capendo tutto quello che serve capire, uno step alla volta.
Possiamo dire che, come quella che abbiamo definito programmazione classica, il Machine Learning è un modo per ottenere dei risultati a partire da un input.

Nel caso della programmazione classica, all’interno di questa black-box, sapevamo esattamente quello che avevamo, e lo sapevamo perché quella famosa logica di risoluzione (l'algoritmo), era una sequenza esatta di istruzioni passo passo.
Con il Machine Learning, abbiamo più o meno la stessa cosa, quello che cambia è il modo in cui sfruttiamo la macchina per raggiungere questo risultato
Abbiamo visto infatti che per noi essere umani è estremamente facile scrivere una serie di istruzioni logiche, che permettono ad una macchina di dirci se un certo numero è positivo o se una data stringa (insieme di caratteri) in ingresso sia palindroma o meno.
Però abbiamo anche capito che mentre per noi è semplice riconoscere un cane da un gatto in una foto, non ci riesce altrettanto facilmente, scrivere delle istruzioni precise affinché una macchina possa farlo per noi.

Proprio partendo dal problema di CANI VS GATTI, nel 1949 Arthur Samuel, un ricercatore IBM e pioniere dell’Intelligenza Artificiale, incominciò a lavorare a un metodo diverso per permettere alle macchine di risolvere i problemi.
La sua idea (rivoluzionaria) di base era questa: invece di dire a un computer i passi esatti necessari per risolvere un problema, mostriamogli degli esempi specifici di come il problema è stato risolto e lasciamogli poi capire da solo come risolvere il problema nella sua forma generale.
Fermiamoci un momento a riflettere su quanto abbiamo appena detto.
Se pensiamo infatti a quello che abbiamo imparato nel capitolo precedente su come si scrive un programma attraverso quella che abbiamo chiamato programmazione classica, pensare a un approccio in cui lasciamo che un computer impari da solo come risolvere un problema tramite esempi del problema risolto, suona totalmente assurdo.
Da un certo punto di vista, un discorso del genere suona come se un veterinario dicesse di smettere di dare da mangiare ai nostri cani e di fargli vedere come prepararlo da soli, per poi lasciare che se lo facciano da soli.
Questo concetto suona estremamente innovativo ancora oggi e posso solo immaginare quanto potesse apparire rivoluzionario nel 1949.
Eppure questa idea si è dimostrata tanto valida che nel 1969 un computer che lavorava utilizzando completamente questo approccio, è stato in grado di battere il campione di scacchi del Connecticut.
Forse oggi questo non sembra poi tanto incredibile, ma nel 1969 una macchina che batte un campione di scacchi è qualcosa che lascia il segno, a maggior ragione se la macchina è progettata per imparare da sola.
Come funziona?
Ok, ma come funziona questa cosa?
Come fa un computer a imparare dagli esempi che gli forniamo? E soprattutto cosa significa che un computer impara?
Qui ovviamente entriamo in un campo piuttosto tecnico e delicato, fatto di matematica, tante equazioni lineari e non lineari, e tantissimi parametri.
Ma a noi, in questo contesto, tutto questo non interessa. Eviteremo quindi di entrare in dettagli che non ci servono e di complicarci la vita con formule inutili ai fini di quello che vogliamo ottenere.
Ci concentreremo invece sul capire tutto quello che ci serve, in modo tale che alla fine di questo post avrai acquisito le conoscenze di base su cos’è il Machine Learning e come funziona nel suo complesso.
Iniziamo con una definizione più o meno formale e poi, nel resto della lezione approfondiremo meglio questa definizione.
Possiamo definire il Machine Learning come un’applicazione dell'Intelligenza Artificiale che fornisce a un sistema di calcolo, le capacità di imparare e migliorare dei dati forniti.
In contrapposizione a quanto abbiamo visto nel capitolo sulla programmazione classica, quindi, in questo caso non c'è nessun programmatore che fornisca al computer delle istruzioni esatte che gli indichino cosa fare esattamente per risolvere il problema, ma ci limitiamo invece a fornire alla macchina dei dati con degli esempi chiari di risoluzione del problema per poi lasciare che sia il computer stesso a trovare un modo per risolvere una qualunque istanza di quel problema.
È per questo motivo che quando parliamo di Machine Learning parliamo di apprendimento automatico: la macchina infatti impara da sola, identifica pattern, sequenze, regolarità e irregolarità nei dati a disposizione e successivamente, utilizza quello che ha imparato per generalizzare una soluzione a nuovi problemi della stessa classe che non ha mai affrontato prima.
Se questo già di per sé è interessante, ancora più interessante è il fatto che tramite questa tecnologia, la macchina migliora sbagliando.
Tramite gli errori, infatti, la macchina apprende e impara a mettere nel corretto ordine le informazioni ricevute.
Ok, fermi un attimo, come fa un computer a imparare dagli errori?
Qui le cose ovviamente si fanno complesse, ma noi cerchiamo di tenerle semplici e di portarci a casa quello che ci serve.
Semplificando moltissimo dividiamo il tutto in quattro principali pezzi del puzzle:
- L'architettura
- Il dataset
- La fase di training
- Il modello
Non preoccupatevi, ora mettiamo tutto in ordine
L’Architettura

L'architettura possiamo interpretarla come lo scheletro del nostro sistema, progettata in modo tale che si presti bene alla risoluzione di una specifica classe di problemi.
Entrare nei dettagli qui, ha poco senso.
Ci basta sapere che un’architettura si può progettare da zero oppure si può sfruttare una delle tante architetture già conosciute in grado di lavorare bene con specifiche classi di problemi.
In letteratura esistono moltissimi tipi di architetture studiate ed ottimizzate per risolvere problemi specifici.
In generale dunque, una delle prime fasi quando ci si approccia allo sviluppo di una Intelligenza Artificiale è quella di individuare la migliore architettura, o il miglior set di architetture, sulla base della tipologia di problemi che vogliamo risolvere.
Il Dataset

Il dataset possiamo vederlo come l'insieme dei dati da cui vogliamo che la nostra Intelligenza Artificiale impari. In determinati contesti (che ci saranno più chiari nei prossimi post di questa serie), potremmo quasi vederli come quei famosi esempi di come risolvere il problema di cui parlava Arthur Samuel nel 1949.
È facile capire quindi che il termine dataset rappresenta un concetto molto generico ed è strettamente correlato al problema che vogliamo risolvere.
Ad esempio, nel caso di un’Intelligenza Artificiale che deve riconoscere se in una foto ci sono cani o gatti, il nostro dataset consisterà in una lista di foto di cani e di gatti contrassegnate da una etichetta, che indica proprio se nella foto c'è un cane oppure un gatto
Nei prossimi capitoli vedremo qualche esempio concreto di alcune categorie di Machine Learning e avremo modo di approfondire il discorso dataset.
La fase di training
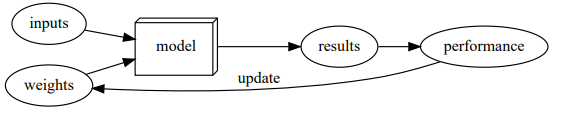
La fase di training, poi, è la parte più pratica di tutto questo processo.
E probabilmente anche quella che può sembrare un po' più magica.
In pratica in questa fase prendiamo la nostra architettura, le diamo in pasto i dati presenti nel nostro dataset e lasciamo che questa impari dai dati, estraendo delle strutture intrinseche (che tecnicamente si chiamano features) che noi stessi non saremmo in grado di razionalizzare e scrivere attraverso una sequenza di passaggi logici, che gli possano permettere di capire come risolvere il problema in questione, in maniera generale.

Per essere un po’ più precisi in realtà, nel Machine Learning più basilare, questo processo di Features Extraction ha bisogno di un intervento manuale da parte di operatori umani con una conoscenza specifica nel dominio di appartenenza dei dati in questione.
Ma per quello che a noi interessa capire in questo contesto, possiamo tranquillamente bypassare questo fatto dato che, come vedremo più nel dettaglio tra qualche capitolo, il Deep Learning ci viene incontro e in molti casi ci permette sempre più di semplificare questo processo, automatizzando (o comunque semplificando di molto) la fase di estrazione delle features.
Ma di questo ne parleremo meglio tra più avanti in uno dei prossimi capitoli.
Il Modello
Finita la fase di training otteniamo un'architettura che possiamo definire ‘specializzata’ e che chiamiamo modello e che, a partire da un elemento in input, sarà in grado di darci in output, una o più soluzioni con un certo grado di affidabilità (che dipende strettamente da tutti i punti precedenti)
Ed è proprio questo il fulcro di questa tecnologia.
Non siamo noi a dire alla macchina come risolvere il problema ma è la macchina a capirlo da sé osservando alcuni esempi del problema risolto.
Ovviamente quello che succede sotto è molto tecnico per entrare nello specifico in questo contesto e va molto al di là di quello che ci interessa capire. Ma è qualcosa di talmente affascinante che credo valga la pena di approfondire un po', mantenendo comunque le cose semplici.
Supponiamo di voler progettare un’Intelligenza Artificiale che, data una foto, ci dica se sia la foto di un gatto oppure di un cane.

Prendiamo allora il nostro dataset composto da un gran numero di foto etichettate (gatto, cane, gatto, gatto, cane, etc, etc), lo passiamo alla nostra architettura e diamo il via alla fase di training.
Che succede quindi a questo punto?
Per farla semplice, diciamo che il nostro modello a questo punto proverà a indovinare, andando praticamente a caso e, per ogni foto nel dataset proverà a dire (casualmente) se nella foto c'è un cane oppure un gatto.
Alla fine di questo primo round (che tecnicamente si chiama epoca) il modello confronterà le sue predizioni con i dati reali (confrontando cioè per ogni singola foto, le sue predizioni con le etichette nel dataset).
A quel punto il modello osserverà quanto ci è andato vicino e quanto invece ha sbagliato e proverà così a correggere il tiro.
Tecnicamente parlando, quello che avviene è che il modello proverà a minimizzare l'errore lavorando sulla minimizzazione di uno strumento matematico chiamato funzione di costo, generalmente attraverso un processo chiamato Stochastic Gradient Descent, che in base al calcolo della derivata della funzione di costo relativamente ai pesi del modello, aggiornerà questi ultimi nella direzione di decrescita del gradiente con un fattore moltiplicativo chiamato learning rate, così da andare passo passo verso un minimo della funzione di costo, ma qui le cose iniziano a farsi troppo tecniche e, per questa serie non tecnica non ci interessano, quindi andiamo avanti.
Il modello, perciò, impara dagli errori: prova, sbaglia, osserva i suoi errori, prova di nuovo, sbaglia di nuovo, osserva di nuovo.
E così via, fino a quando non sarà in grado di predire il risultato corretto con una buona accuratezza.
Da notare bene che qui si è parlato di predire con buona accortezza.
Non otteniamo mai infatti, modelli con un'accuratezza del 100% su ogni singolo elemento in input (anche un essere umano a volte può sbagliare tra un cane e un gatto soprattutto con una informazione di partenza poco chiara) , soprattutto su problemi complessi. Ma i livelli di accuratezza che siamo in grado di raggiungere oggi sono già molto soddisfacenti (praticamente approssimabili100% per problemi così semplici come immagini di cani e gatti)
E ovviamente, più andiamo avanti con questa tecnologia, più la qualità dei dataset aumenta, più la nostra capacità di progettare buone architetture aumenta e più questa affidabilità tende a migliorare.
Quindi ricapitoliamo.
Definiamo un’architettura ottimale per la risoluzione del problema che abbiamo di fronte.
Prendiamo il nostro dataset e lo diamo in pasto all’architettura.
Attraverso una fase di training otteniamo un modello con un livello di accuratezza che ci soddisfa per il problema che abbiamo bisogno di risolvere
A questo punto la magia è fatta. Infatti, se i punti precedenti sono stati fatti correttamente su un problema su cui avesse senso farlo e con una corretta architettura per il problema stesso, avremmo ottenuto un modello che sarà in grado di risolvere il problema anche con dati che non appartengono al dataset di partenza e, quindi, con dati che non ha mai visto prima.
In pratica, tornando al nostro esempio di cani e gatti, questo significa che conclusa con successo la fase di training, avremmo ottenuto un modello che, data una qualunque foto di un cane o di un gatto, sarà in grado di dirci con buona accuratezza se in quella foto c'è un cane o c'è un gatto.
Attraverso la fase di training e un processo di tentativi ed errori quindi, il nostro modello è stato in grado di identificare dalle strutture, dei pattern, degli schemi, che gli hanno permesso di trovare il modo per distinguere un cane da un gatto.
E se ci pensiamo un attimo, non è esattamente quello che fa anche il nostro cervello? Quanti errori dobbiamo commettere prima di imparare qualcosa? Quante volte bisogna cadere per imparare a camminare?
Ovviamente questa metodologia ha poco senso per i problemi visti negli esempi della programmazione classica, anche perché in quei casi ottenevamo programmi in grado di risolvere il problema fornito con una accuratezza del 100%, mentre in questo caso il massimo che potremmo ottenere è una buona affidabilità nella risoluzione del problema.
Sebbene dunque teoricamente parlando potremmo utilizzare questo metodo anche per la risoluzione di quei problemi (ad esempio creando un dataset con stringhe e le rispettive stringhe inverse da usare in una fase di training), non avrebbe senso farlo, in quanto ci complicheremmo la vita inutilmente e otterremmo un sistema meno affidabile e, computazionalmente parlando più complesso, di quello che possiamo ottenere con la “programmazione classica”.
Ma che succede nel momento in cui entriamo nel mondo dei problemi che non siamo in grado di risolvere attraverso una sequenza ben definita di istruzioni precise?
Beh, quello che succede è che non dobbiamo più preoccuparci di trovare un modo per spiegare esattamente alla macchina come risolvere il problema (cosa che peraltro non sappiamo fare), ma dobbiamo invece:
- Progettare o individuare la giusta architettura che lavori bene con il problema specifico.
- Definire un dataset per insegnare alla macchina quello che vogliamo ottenere
- Gestire la fase di training in modo da ottenere il miglior modello per risolvere il nostro problema
Sia chiaro, ovviamente abbiamo semplificato tutto in maniera importante.
- Non abbiamo parlato di come definire effettivamente un'architettura adatta al problema che ci troviamo davanti.
- Non abbiamo parlato della complessità computazionale necessaria per la fase di training.
- Non abbiamo parlato dei problemi del overfitting e dell’underfitting.
- Non abbiamo parlato della complessità nell'implementazione di un dataset di qualità in grado di permettere al modello di essere davvero utilizzabile in un contesto reale.
- Non abbiamo parlato della necessità di dividere il dataset stesso in tre diversi segmenti (training, validazione e testing).
- E abbiamo inoltre omesso tutta una serie di questioni tecniche importanti
Ma per gli scopi di questa guida non tecnica all'Intelligenza Artificiale, tutto questo non ci interessa.
Quello che invece ci interessa davvero è l'aver capito la netta differenza che c'è tra la programmazione classica e questo nuovo approccio.
Da una parte abbiamo un set di istruzioni chiare che la macchina si limita a decodificare ed eseguire, pari pari.
Dall'altra parte invece, abbiamo un processo di apprendimento basato su esempi reali del problema risolto che ci permetterà poi di ottenere un modello in grado di risolvere con un buon grado di affidabilità qualunque istanza del problema.
Ma soprattutto, quello che ci interessa capire veramente, è che questa tecnologia ci permette di risolvere problemi che non saremo altrimenti in grado di far risolvere a un computer.
Non stiamo parlando quindi di un modo di programmazione diverso rispetto a un altro, ma stiamo letteralmente parlando di un nuovo paradigma concettuale che ci permette di risolvere problemi altrimenti irrisolvibili.
E soprattutto, non è necessario essere in grado di descrivere come risolvere questi problemi, ma è sufficiente limitarci a sviluppare e trainare un modello affinché impari da sé a risolvere il problema.
E se già questo pare rivoluzionario, tieniti forte perché non è ancora tutto!
Possiamo suddividere infatti il Machine Learning in tre grandi categorie e, quella che abbiamo visto negli esempi fino a ora, è solo una di queste categorie.

A partire dal prossimo capitolo, vedremo le tre categorie di Machine Learning e i loro principali utilizzi.
- Apprendimento Supervisionato (o Supervised Learning)
- Apprendimento Non Supervisionato (o Unsupervised Learning)
- Reinforcement learning
Successivamente, parleremo di Reti Neurali, Deep learning e Modelli Generativi.







