
Apprendimento Supervisionato (Supervised Learning)
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
Nei post precedenti di questa serie, abbiamo visto la differenza tra quella che abbiamo spartanamente definito programmazione classica e l'Intelligenza Artificiale e, in particolare, abbiamo visto come, grazie al Machine Learning, siamo in grado di risolvere anche quei problemi per cui non saremmo effettivamente in grado di descrivere una sequenza di istruzioni precise per la loro risoluzione, cosa che invece avremmo dovuto fare con la programmazione classica.
Alla fine del capitolo precedente, abbiamo poi detto che possiamo dividere il Machine Learning in tre categorie differenti:
- Apprendimento Supervisionato (o Supervised Learning)
- Apprendimento Non Supervisionato (o Unsupervised Learning)
- Reinforcement Learning
In questo e nei prossimi due capitoli, analizzeremo più nel dettaglio queste tre categorie e faremo alcuni esempi e, per ognuna di queste categorie, capiremo per cosa ognuna di esse ci può essere utile e quali problemi può aiutarci a risolvere.
Nello specifico, in questo capitolo, parleremo dell’Apprendimento Supervisionato (o Supervised Learning).
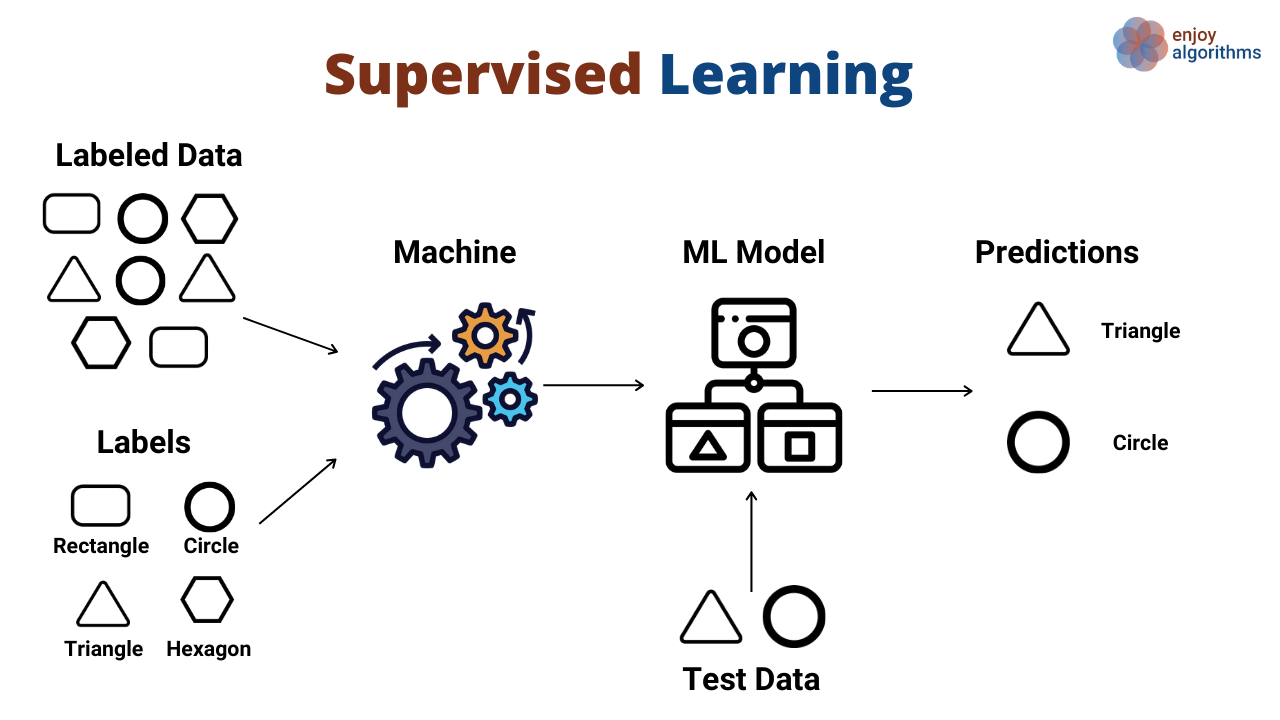
In questa tipologia di apprendimento, noi lasciamo che la macchina (o il modello) apprenda imparando a trovare dei pattern attraverso l’analisi di esempi di problema risolto, tramite una lista di input e output (dataset) che siamo noi stessi a fornirgli attraverso una specifica codifica del dataset.
In pratica questa è esattamente la categoria di apprendimento utilizzata negli esempi dei precedenti capitoli.

Dato il modo in cui lavora, l'Apprendimento Supervisionato è molto utile per realizzare modelli in grado di svolgere alcune principali tipi di operazioni, tra cui:
- Classificazione
- Regressione
Classificazione

La classificazione, nella pratica, non è altro che ciò che abbiamo visto nell’esempio di cani e gatti del capitolo precedente.
Una volta trainato il modello per distinguere le immagini di un cane da quelle di un gatto, possiamo utilizzarlo su immagini che il modello non ha mai visto e ottenere, con una buona affidabilità, una classificazione di quella immagine.
L’idea di base è quella di creare un modello in grado di classificare un certo dato in input, assegnandogli una categoria tra N possibili categorie.
Non serve dire ovviamente che una stessa tecnologia si può utilizzare per costruire un modello in grado di classificare un'ampia gamma di cose e non solo di determinati elementi in un'immagine o in un video. (che a conti fatti non è altro un insieme di immagini che scorrono ad una certa velocità)
Possiamo anche utilizzarlo per risolvere problemi di classificazione totalmente diversi.
Ad esempio, possiamo trainare un modello di classificazione a distinguere una recensione positiva da una classificazione negativa.
E ormai sappiamo come fare.
- Progettiamo o individuiamo un'architettura adatta alla risoluzione di questo problema.
- Creiamo un dataset composto da un insieme di recensioni etichettate come positive o negative
- E infine trainamo il modello utilizzando i dati all'interno del nostro dataset.
Alla fine di questo processo, se svolto in maniera corretta, avremo ottenuto un modello che, data una qualunque recensione, è in grado di dirci, con una buona approssimazione, se questa recensione è positiva o negativa.
Attenzione però, qui ci sono diversi dettagli da considerare, infatti per capire se una recensione è positiva o negativa, ci sono particolari come le similitudini, l’ironia, etc, che il modello deve essere in grado di considerare.
Più avanti, nel capitolo dedicato al Natural Language Processing, analizzeremo più nel dettaglio questo concetto.
Regressione

La regressione invece, ci permette di creare un modello che possa essere utile nello stimare una misura.
Il sistema di funzionamento è lo stesso.
L’idea di base è quella di creare un modello in grado di predire il valore di una certa variabile (chiamata variabile dipendente) partendo dai valori di altri fattori che conosciamo (che chiamiamo variabili indipendenti).
Supponiamo, ad esempio, di voler realizzare un modello che ci permetta di stabilire una stima delle vendite annuali (variabile dipendente) al variare del valore delle spese di advertising (variabile indipendente).
Quello che possiamo fare è trainare un modello sulla base dei dati storici della nostra azienda (ovviamente dobbiamo avere a disposizione un quantitativo sufficienti di dati), facendo in modo che il modello impari a riconoscere la correlazione tra spese di advertising e vendite annuali.
Nell'esempio di classificazione cane o gatto, trainavamo il nostro modello passandogli un insieme di immagini di cani e gatti che etichettavamo in maniera appropriata, in modo tale che il nostro modello potesse provare a indovinare, verificare quanto ci fosse andato vicino e poi aggiustare il tiro.
In questo esempio di regressione facciamo qualcosa di molto simile.
Se prima il nostro input era un’immagine e il nostro output era invece un’etichetta che utilizzavamo per dire al modello se si trattasse di un cane un gatto, adesso il nostro input sarà la spesa di advertising sostenuta in un certo anno e il nostro output sarà il totale delle vendite per quell'anno specifico.
In pratica prima costruivamo il nostro dataset mettendo al suo interno molte immagini etichettate. Adesso invece lo costruiamo mettendo al suo interno una lista di quanti più esempi possibili del rapporto di spesa di advertising e totale delle vendite degli anni passati.
Il modello per il resto si comporterà nello stesso modo.
Inizierà andando a caso e per ogni elemento nel dataset proverà a stimare un possibile totale di vendite di quell'anno. Verificherà poi quando ci è andato vicino e lavorerà infine per abbassare il più possibile la funzione di costo.
Attraverso questo processo sarà in grado di trovare una correlazione che lega l'input (spesa di advertising) con l’output (totale vendite dell'anno).
E dopo la fase di training, se nell'esempio di cane e gatto otteneva un modello che era in grado di dirci con una certa affidabilità se in un'immagine che non aveva mai visto prima ci fosse un cane o un gatto, in questo caso otterremo un modello che a partire da un valore di spesa advertising potenziale sarà in grado di dirci (stimare) con una certa affidabilità quello che potrebbe essere il totale delle vendite.
Inoltre, possiamo rendere le cose un pochino più interessanti andando a considerare input un po' più complessi di una singola variabile indipendente.
Nell'esempio appena fatto, infatti, il nostro input era il solo valore della spesa di advertising ma nulla ci vieta di creare modelli più complessi che lavorano su variabili indipendenti multiple, come ad esempio eventuali KPI pubblici del settore in cui operiamo che possono influenzare le nostre vendite.
Semplicemente prepariamo un dataset che contenga come input la fotografia di tutti questi valori per ogni singolo anno e come output quello che vogliamo che il modello impari a stimare (ad esempio il totale delle vendite) e poi lasciamo che durante la fase di training, il modello impari e trovi la correlazione tra questi dati e la nostra variabile dipendente.
In questo capitolo abbiamo parlato dell'Apprendimento Supervisionato e ne abbiamo visto gli utilizzi principali, nei prossimi due capitoli di questa serie, invece, andremo a parlare dell'Apprendimento Non Supervisionato (o Unsupervised Learning) e del Reinforcement Learning.







