
Apprendimento non Supervisionato (Unsupervised Learning)
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
In questo capitolo parliamo di Apprendimento non Supervisionato Nel capitolo precedente abbiamo parlato di Apprendimento Supervisionato e abbiamo visto due dei principali utilizzi di questa tecnologia:
- La classificazione: che ci permette di classificare cose, come ad esempio cani o gatti, recensioni buone o cattive, macchine, aerei, treni.
- La regressione: che ci permette di predire cose, come ad esempio le possibili vendite a partire dalla spesa di advertising
Ma come abbiamo detto però, questa è solo una delle tre macro-categorie in cui possiamo dividere il Machine Learning.
In questo capitolo invece, parleremo di Apprendimento Non Supervisionato (Unsupervised Learning)
Per capire questa seconda categoria, ci basta partire dalla prima ed estendere un po' il nostro ragionamento.
Come sempre, il mio scopo in questo post, non è quello di fornirti dei concetti fini a se stessi, ma quello di portarti ad acquisire la conoscenza necessaria per capire le basi concettuali che sono dietro termini apparentemente complessi.
Mi raccomando, prima di procedere con la lettura di questo capitolo, è molto importante che tu abbia letto e capito quanto spiegato nel capitolo precedente di questa serie: Apprendimento Supervisionato.
Per fare un brevissimo recap, nell’Apprendimento Supervisionato abbiamo detto che durante la fase di training, il modello attraverso un processo di prove e fallimenti svolto sui dati all'interno del dataset più e più volte (che abbiamo definito epoche), impara a minimizzare la funzione di errore, in modo da ottenere la maggiore affidabilità possibile.
Abbiamo inoltre detto che, per fare questo, il modello estrae dai dati pattern, schemi e strutture che gli consentono di individuare la correlazione che sussiste fra i dati in input e quelli in output.
Ma facciamo un passo indietro.
Siamo partiti dal mondo della programmazione classica, in cui eravamo noi a dover dire esattamente al computer cosa doveva fare passo passo.
Siamo poi passati per Arthur Samuel che ha detto che ormai era tempo di smettere di dire al computer quello che doveva fare, ma che dovevamo limitarci a fornirgli degli esempi del problema risolto e poi lasciare che si arrangiasse a capire come risolverlo da solo.
Che succede allora se facciamo un nuovo salto di paradigma e diciamo “basta dare degli esempi al computer di qual è la soluzione, passiamogli il problema e poi lasciamo che si arrangi da solo”?
Ora sia chiaro, non è esattamente così semplice, ma rende bene l'idea per quello che ci interessa sapere.
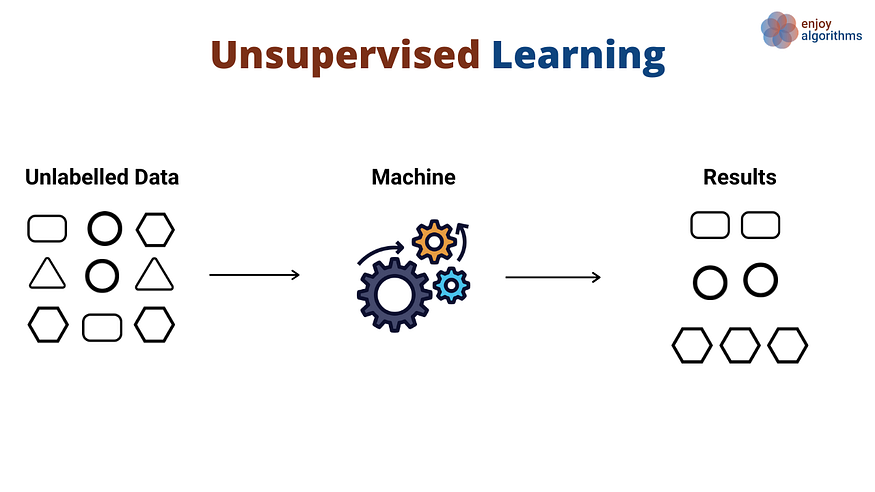
Mentre con l'Apprendimento Supervisionato siamo noi a dover impostare il dataset in modo tale che il modello possa imparare attraverso degli esempi di soluzione forniti da noi, con l'Apprendimento Non Supervisionato, noi non dobbiamo fornire alcuna soluzione nel dataset ma ci limitiamo a dare alla macchina i dati grezzi.
Con l’Apprendimento Non Supervisionato, in pratica, il modello è lasciato libero di trovare le connessioni che intercorrono tra i dati.
Tra gli utilizzi più comuni dell'Apprendimento Non Supervisionato abbiamo:
- Clustering
- Association
- Dimensionally Reduction
Clustering
Iniziamo dal clustering

Il concetto, semplificando molto, è questo: noi prendiamo un insieme di dati totalmente mescolati, li diamo in pasto alla macchina e alla fine otteniamo in uscita un ordinamento di dati che il modello è stato in grado di trovare all'interno dei dati stessi.
In pratica il modello crea i clusters a partire dai dati grezzi.
Facciamo un esempio pratico prendendo il nostro dataset di immagini con cani e gatti.
Immaginiamo però questa volta, di non fornire nessuna etichetta che dica al modello se quello che c'è nelle immagini siano cani o gatti.
Semplicemente prendiamo il nostro insieme di immagini di cani e gatti mescolate e senza etichette, le passiamo a nostro modello e lasciamo che tragga le sue conclusioni.
Alla fine del processo, quello che otterremo sarà una suddivisione (clusterizzazione) dell'insieme di partenza diviso secondo un pattern che il modello ha identificato all'interno dei dati e, nel nostro esempio, è molto probabile che avremmo in uscita due clusters esatti: cani da una parte e gatti dall'altra.
In questo contesto in pratica il nostro obiettivo non è trainare il modello affinché potremmo poi utilizzarlo con nuovi dati in futuro, quello che invece ci interessa con il clustering, è proprio il risultato stesso sui dati di partenza che otteniamo alla fine del lavoro.
È importante notare qui come, semplificando moltissimo questo concetto, che noi ci limitiamo a passare i dati dal nostro modello per poi osservarne il risultato che il modello tira fuori dai dati di partenza.
Ovviamente abbiamo il controllo su tutta una serie di parametri che potranno poi influenzare il risultato del clustering ma, nella pratica è il modello che stabilisce, a conti fatti, la clusterizzazione.
Facciamo un esperimento mentale, per capire meglio.
Supponiamo di prendere il dataset di cani e gatti, togliere tutte le foto dei cani e passare al modello solo le foto dei gatti.
A questo punto, ovviamente, il risultato della clusterizzazione sarà diverso dal caso precedente.
Potremmo ottenere una clusterizzazione di gatti di colori differenti, oppure potremmo ottenere una clusterizzazione di cuccioli e gatti adulti, oppure ancora potremmo avere una clusterizzazione composta da gatti di razza diversa. Questo dipende da tantissimi fattori (composizione del dataset, parametri di training, architettura, etc).
Ok, ma nella pratica a cosa ci serve tutto ciò?
Sicuramente è molto utile in ambito scientifico.
Pensiamo infatti a un esperimento in cui si raccolgono migliaia e migliaia di dati. Grazie al clustering siamo in grado di dare un ordine a questi dati, capendone velocemente gli schemi che li compongono senza dover analizzare tutta questa grande mole di dati manualmente.
Allo stesso tempo, il clustering può essere uno strumento utile per semplificarsi la vita e ottimizzare tempi e risorse.
Ad esempio, un mio amico lavora come ingegnere per una società che si occupa di intelligenza artificiale. Un giorno nella sua azienda si sono ritrovati ad avere un problema: avevano una grande quantità di immagini di documenti digitali tutti mescolati tra di loro, suddivisi tra carte d'identità e altri documenti di vario genere e avevano bisogno di separare le carte d'identità dal resto.
Ovviamente potevano prendere un dipendente che si mettesse lì con tanta pazienza a suddividere i file ma parlavamo di migliaia e migliaia di file. Sprecare una risorsa umana per un compito del genere non sarebbe stato all'altezza di una società che si occupa di Intelligenza Artificiale (ed anche intellettualmente poco stimolante per la risorsa stessa).
Quale migliore applicazione del clustering per risolvere questo problema?
La tecnica del clustering può essere sfruttata anche come step precedente per l’Apprendimento Supervisionato quando però non sì ha ancora una corretta etichettatura dei dati.
Ad esempio, se volessimo realizzare un classificatore (usando quindi l’Apprendimento Supervisionato) in grado di classificare un certo numero di oggetti appartenenti a N classi diverse all’interno del nostro dataset, ma non abbiamo a disposizione un dataset già bello etichettato (come spesso accade nella vita reale), come possiamo fare?
Certo, potremmo metterci ed etichettare manualmente il nostro dataset. Oppure, se la natura stessa dei dati lo permette, una via più smart potrebbe essere quella di sfruttare il potere del clustering, dandogli in pasto il nostro dataset e lasciare che sia il sistema stesso a fare una clusterizzazione del dataset.
Certo dovremmo accertarci che il clustering abbia fatto un buon lavoro facendo un check sui dati e sistemando dove necessario, ma ci saremo comunque risparmiati molto lavoro operativo.
Inoltre il clustering è un'applicazione utile anche nel business.
Può essere ad esempio utilizzato per capire il sentiment che le persone hanno nei confronti di un'azienda o di un brand, raccogliendo un gran numero di recensioni e lasciare che la macchina le clusterizzi in modo da poter identificare eventuali punti di miglioramento o anche possibili angle con cui attaccare il mercato.
Ma le possibili applicazioni non finiscono qui.
Immaginiamo infatti di avere un insieme di dati demografici sul nostro target o sui nostri clienti, preparare un dataset con tutti questi dati e passarli al nostro modello.
Alla fine avremo ottenuto una segmentazione del nostro target che ci permetterà di ottenere informazioni di alto valore per il nostro business.
E non solo un'analisi del genere ci può permettere di ottenere più informazioni sui nostri clienti, ma ci può anche aiutare a ottimizzare le nostre offerte, facendo arrivare il prodotto giusto alle persone giuste.
Supponiamo infatti di ottenere N clusters diversi a partire dai dati che abbiamo sui nostri clienti.
A questo punto supponiamo di prendere uno di questi cluster ottenuti e che analizzandolo ci rendiamo conto che lo 85% delle persone all'interno di questo cluster ha acquistato un certo prodotto.
Vien da se che questo prodotto può potenzialmente interessare anche al 15% di persone all’interno del cluster! E restano da analizzare ancora tutti gli altri n-1 clusters.
E partendo da questo discorso, arriviamo a parlare dell’altro utilizzo più comune dell’Apprendimento Non Supervisionato: l’association.
Association
L’association è una tecnica di Unsupervised Learning che ci permette di trovare, per l’appunto, le associazioni esistenti all’interno del dataset.
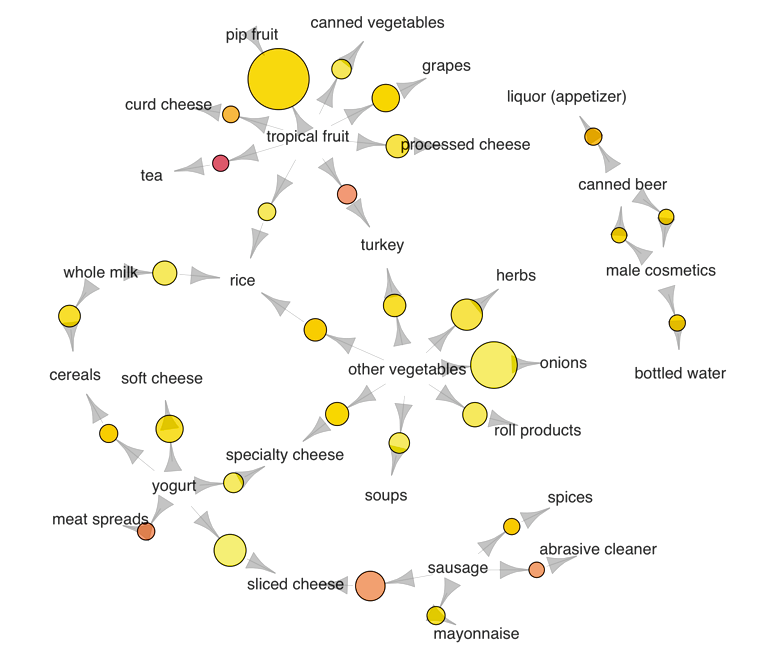
Questa tecnica viene utilizzata per identificare nuovi e interessanti approfondimenti tra diversi oggetti in un insieme o schemi frequenti nei dati.
Facciamo un esempio pratico di utilizzo di questa tecnica, tornando al mondo del business.
Supponiamo che un’azienda abbia a disposizione un buon quantitativo di dati raccolti nel tempo e che con questi dati costruisca un dataset composto dallo storico degli acquisti negli dei propri clienti.
Attraverso l’utilizzo dell’association quindi, quest’azienda sarebbe in grado di creare una mappa rappresentante i comportamenti di acquisto dei propri clienti così da identificare dei comportamenti di acquisto ricorrenti in modo tale da definire delle regole, ad esempio:
- I clienti che acquistano il prodotto X, in genere acquistano anche il prodotto Y
- I clienti che acquistano il prodotto Z, generalmente lo riacquistano ogni Tot tempo
Inutile dire che a questo punto, l’azienda in questione può sviluppare una strategia di marketing ad hoc proprio sulla base di questi informazioni.
Dimensionally Reduction

Per concludere, un altro uso comune dell’Apprendimento non Supervisionato, è il Dimensionally Reduction che, detta tecnicamente ha lo scopo trasformare i dati portandoli da uno spazio a più alta dimensionalità in uno spazio a dimensionalità più bassa, facendo però in modo che la nuova rappresentazione mantenga alcune proprietà significative dei dati originali, idealmente vicini alla sua dimensione intrinseca.
Questo processo è estremamente utile per molti scopi, tra cui la riduzione del rumore nei dati e per la fase di Features Extraction di cui abbiamo già accennato qualcosina in uno dei capitoli precedenti, ma di cui parleremo un po’ più a fondo più avanti in questa serie.
Ma per quanto riguarda il Dimensionally Reduction, questo è tutto quello che ci serve sapere in questa guida non tecnica all'Intelligenza Artificiale, dunque non entreremo in dettagli che non aggiungono utilità a quelli che sono i nostri fini!
Ricapitolando, in questo capitolo abbiamo parlato dell'apprendimento non supervisionato e delle sue principali applicazioni pratiche: Clustering, Association e Dimensionally Reduction.
Abbiamo capito cos’è e come funziona e, se da oggi iniziamo a farci caso, quando ce lo ritroveremo davanti saremo in grado di riconoscerlo.
L'Apprendimento Supervisionato e l’Apprendimento non Supervisionato che abbiamo trattato in questo e nel capitolo precedente, sono due concetti estremamente interessanti, ma ti assicuro che la categoria che tratteremo nel prossimo post di questa serie (il Reinforcement Learning), non ha nulla da invidiare a queste due.







