Discesa del gradiente: una rappresentazione visiva
Questo articolo ha l'obiettivo di fornire una panoramica visiva dell'algoritmo di discesa del gradiente, uno dei principali algoritmi di ottimizzazione utilizzati nell'apprendimento automatico per minimizzare la funzione di errore.
Per fare ciò, utilizzeremo la funzione di errore MSE:
$ MSE = \frac{1}{N} \sum_{i=1}^{N}( (Y_i - \hat{Y_i})^2 ) $
Inizieremo creando una distribuzione lineare con del rumore, al fine di mantenere i dati "realistici". Successivamente, utilizzeremo l'algoritmo di discesa del gradiente per ottimizzare i parametri di una semplice regressione lineare fatta manualmente, senza l'utilizzo di librerie di Machine Learning.
In particolare, ci concentreremo sull'ottimizzazione del parametro m (il coefficiente angolare) della retta di regressione e terremo fisso al termine noto il parametro c (distanza dall'origine), in modo da focalizzare il lavoro di ottimizzazione su un solo parametro e lavorare in uno spazio $ R^2$ .
In questo modo, potremo analizzare l'andamento dell'errore sulla funzione di costo $L(m, \overline{c})$ e visualizzare come il valore del parametro m si muove verso il minimo della funzione di errore in ogni epoca. Inoltre, attraverso la visualizzazione dell'andamento della funzione di costo al variare del parametro m, potremo avere una panoramica visiva dell'andamento del parametro in casi particolari, come l'esplosione o la scomparsa del gradiente.
Se vuoi scaricare il notebook associato a questo articolo, così da sperimentare direttamente con le tue mani, puoi farlo da qui: https://github.com/SimoneTruglia/personal-blog-files/blob/main/discesa-del-gradiente-una-rappresentazione-visiva.ipynb
Siamo pronti per iniziare!
Facciamo l'import delle varie librerie che andremo ad utilizzare
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import random
from PIL import Image
from IPython.core.display import HTMLInizializzazione del Dataset
Iniziamo generando una distribuzione lineare con coefficiente angolare (slope) e una distanza dall'origine (intercept) creati randomicamente.
Per dare senso ai dati rendendoli 'realistici' aggiungiamo all'equazione della distribuzione lineare un rumore creato attraverso una distribuzione normale data da np.random.normal()
noise_factor controlla il rumore della distribuzione e verrà utilizzato come parametro di deviazione standard della distribuzione di rumore. Maggiore sarà il valore, maggiore sarà il la distanza dalla distribuzione normale dei punti di rumore
Infine plottiamo il dataset ottenuto e scriviamo i valori "reali" del coefficiente angolare (slope) e della distanza dall'origine (intercept), che saranno poi i parametri m e c da identificare nella nostra regressione lineare
num_points = 100
from_x = 0
to_x = 15
# Parametro per controllare il rumore della distribuzione
noise_factor = 3
slope = random.uniform(0, 10)
intercept = random.uniform(0, 10)
X = np.linspace(from_x, to_x, num_points)
Y = slope*X + intercept + np.random.normal(from_x, noise_factor, num_points)
print ("> real_slope (m): {} \n> real_intercept (c): {}". format(slope, intercept))
# Plot the data
plt.scatter(X, Y)
plt.show()> real_slope (m): 9.540138588033479 > real_intercept (c): 11.68243651564374

Inizializzazione dei parametri e definizione degli iperparametri
PARAMETRO M
Andiamo a settare randomicamente il paremtro m in modo tale che successivamente utilizzeremo la tecnica della discesa del gradiente per ottimizzare questo valore. Volendo possiamo settarlo anche a zero come valore di partenza, ma settarlo ad un valore randomico aiuta poi successivamente ad apprezzare meglio il diverso comportamento del gradient descent in funzione del valore iniziale di m
PARAMETRO C
Per semplicità, il parametro c lo fissiamo direttaemente noi al valore noto reale, perché in questo contesto vogliamo tenere il lavoro singolarmente sul parametro m, in modo da lavorare in $R^2$ quando successivamente analizzeremo l'andamento dell'errore su $L(m, \overline{c})$
IPERPARAMETRI
Gli iperparametri lr (Learning Rate) e epochs (numero di epoche) possono essere modificati per testare le conseguenze di queste modifiche sul comportamento del modello
#-------------------
# Parametri
#-------------------
# inizializziamo m a zero
m = 0
# fissiamo c al paramentro reale per concentrarci
# solamente sull'andamento del parametro m
c = intercept
#-------------------
# Iper parametri
#-------------------
# learning Rate
lr = 0.001
# Numero di epoche
epochs = 100 Definizione della funzione di errore e delle relative derivate
Definiamo la funzione di funzione di errore e le relative derivate rispetto a m e rispetto a c
In questo contesto utilizziamo la MSE.
$MSE = \frac{1}{N} \sum_{i=1}^{N}( (Y_i - \hat{Y_i})^2 )$
Nel contesto di questo notebook, la derivata rispetto a c non verrà mai utilizzata, poiché come spiegato sopra, il parametro c è già definito sul termine noto e resterà costante per tutto il tempo (quindi non verrà ottimizzata dal gradient descent). Per completezza però, definiamo comunque la derivata della funzione di errore rispetto a c
Derivata rispetto a m
$\frac{\partial \mathrm{MSE}}{\partial m} = - \frac{2}{N} \sum_{i=1}^{N}( X_i(Y_i - \hat{Y_i})^2 ) $
Derivata rispetto a c
$\frac{\partial \mathrm{MSE}}{\partial c} = - \frac{2}{N} \sum_{i=1}^{N}( (Y_i - \hat{Y_i})^2 ) $
# Definizione della funzione di errore. In questo contesto utilizziamo la MSE
def f_error(n, m, c, X, Y):
return (1/n) * np.sum( (Y - m*X - c)**2 )
def get_m_derivative(n, X, Y, Y_pred):
return (-2 / n) * sum(X * (Y - Y_pred))
def get_c_derivative(n, Y, Y_pred):
return (-2 / n) * sum(Y - Y_pred)Algoritmo di discesa del gradiente e aggiornaemnto parametri
Andiamo ad effettuare l'algoritmo di discesa del gradiente per il numero di epoche stabilito nella definizione degli iperparametri (nota che per semplicità in questo esempio non c'è early stopping)
Ad ogni epoca:
- calcoliamo il valore della predizione sulla base del valore corrente dei parametri m e c
- utilizzamo la predizione creata per calcolare le derivate della funzione di errore
- aggiorniamo i parametei di conseguenza
Nota che in questo notebook, poiché teniamo il valore di c fisso al suo valore reale, non andiamo a calcolare la derivata della funzione di errore rispetto a c e non andiamo ad aggiornare il valore del parametro c (in quanto questo è già ottimizzato manualmente)
Infine stampiamo alcune informazioni utili per valutare come si è comportato il processo di fit
# numero di esempi del dataset
n = len(X)
# array che conterrà i vari valori assunti dal parametro m dopo ogni epoca
M = []
# array che conterrà tutti i valori assnunti dal parametro m dopo ogni epoca
# nota che nel contesto di questo articolo, c avrà sempre lo stesso valore 'noto'
C = [intercept]*epochs
# array che conterrà i vari valori assunti dall'errore dopo ogni epoca
errors = []
#-------------------------
# Discesa del Gradiente
#----------------------
for i in range(epochs):
# Append sugli array M e errors
errors.append(f_error(n, m, c, X, Y))
M.append(m)
#C.append(c)
# predizioni di y
Y_pred = m * X + c
# derivata prima rispetto ad m e aggiornamento parametro m
D_m = get_m_derivative(n, X, Y, Y_pred)
m -= lr * D_m
#-------------------
# Questa parte qui è disabilitata perché fisso già io C perché voglio solo vedere
# la variazione di M con C conosciuto
#-------------------
# derivata prima rispetto ad c e aggiornamento parametro c
# D_c = get_c_derivative(n, Y, Y_pred)
# c -= lr * D_c
#-------------------
print ("> real_slope (m): {} \n> real_intercept (c): {}". format(slope, intercept))
print("---")
print ("> predicted_slope (m): {} \n> known_intercept (c): {}". format(m, c))
print("---")
print ("> Min Error: {} ".format(min(errors) ) )
# Predizioni
Y_pred = m * X + c> real_slope (m): 9.540138588033479 > real_intercept (c): 11.68243651564374 --- > predicted_slope (m): 9.510489087318472 > known_intercept (c): 11.68243651564374 --- > Min Error: 7.19523915897515
Analizziamo i risultati della fase di training del parametro m
Osserviamo ora come la funzione di ipotesi, tramite l'aggiornamento di epoca in epoca del parametro m, si sia adattata ai dati reale nel modo migliore possibile.
gif_filename = "target_approach.gif"
# Initialize figure
fig, ax = plt.subplots()
# Set axis labels and title
ax.set_xlabel('x')
ax.set_ylabel('y')
# Initialize empty list for frames
frames = []
print('Starting creating the gif frames')
print('---')
# Create the scatter plot for each point
for i in range(len(M)):
ax.set_title(f"E:{i:d} m:{M[i]:.3e} c:{C[i]:.3e} Err: {errors[i]:.3e}")
print(f"E:{i:d} m:{M[i]:.3e} c:{C[i]:.3e} Err: {errors[i]:.3e}")
y_temp = M[i]*X + C[i]
ax.scatter(X, Y)
ax.plot(X, y_temp, color="red")
ax.set_title(f"E:{i:d} m:{M[i]:.3e} c:{C[i]:.3e} Err: {errors[i]}")
# set the tick density on the X and Y axes
ax.locator_params(axis='x', nbins=10)
ax.locator_params(axis='y', nbins=10)
# Save the current plot as a PIL image
fig.canvas.draw()
frame = Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())
frames.append(frame)
# Clear the plot for the next iteration
ax.clear()
# Close the plot to avoid displaying it
plt.close()
print('---')
print('saving the gif (it can take some time, especially with many epoches)')
print('Please waiting...')
# Save the gif
frames[0].save(gif_filename, format='GIF', append_images=frames[1:], save_all=True, duration=100, loop=0)
print('The gif has been successfully created!')
HTML(f'To open it <a href="{gif_filename}" target="_blank"> click here</a>')Starting creating the gif frames --- E:0 m:0.000e+00 c:1.168e+01 Err: 6.825e+03 E:1 m:1.434e+00 c:1.168e+01 Err: 4.924e+03 E:2 m:2.651e+00 c:1.168e+01 Err: 3.554e+03 E:3 m:3.685e+00 c:1.168e+01 Err: 2.565e+03 E:4 m:4.564e+00 c:1.168e+01 Err: 1.852e+03 E:5 m:5.309e+00 c:1.168e+01 Err: 1.338e+03 E:6 m:5.943e+00 c:1.168e+01 Err: 9.667e+02 E:7 m:6.481e+00 c:1.168e+01 Err: 6.992e+02 E:8 m:6.937e+00 c:1.168e+01 Err: 5.063e+02 E:9 m:7.325e+00 c:1.168e+01 Err: 3.671e+02 E:10 m:7.655e+00 c:1.168e+01 Err: 2.668e+02 E:11 m:7.935e+00 c:1.168e+01 Err: 1.944e+02 E:12 m:8.172e+00 c:1.168e+01 Err: 1.422e+02 E:13 m:8.374e+00 c:1.168e+01 Err: 1.046e+02 E:14 m:8.545e+00 c:1.168e+01 Err: 7.743e+01 E:15 m:8.691e+00 c:1.168e+01 Err: 5.785e+01 E:16 m:8.814e+00 c:1.168e+01 Err: 4.373e+01 E:17 m:8.919e+00 c:1.168e+01 Err: 3.354e+01 E:18 m:9.008e+00 c:1.168e+01 Err: 2.620e+01 E:19 m:9.084e+00 c:1.168e+01 Err: 2.090e+01 E:20 m:9.148e+00 c:1.168e+01 Err: 1.708e+01 E:21 m:9.203e+00 c:1.168e+01 Err: 1.432e+01 E:22 m:9.249e+00 c:1.168e+01 Err: 1.234e+01 E:23 m:9.289e+00 c:1.168e+01 Err: 1.090e+01 E:24 m:9.322e+00 c:1.168e+01 Err: 9.869e+00 E:25 m:9.351e+00 c:1.168e+01 Err: 9.124e+00 E:26 m:9.375e+00 c:1.168e+01 Err: 8.586e+00 E:27 m:9.395e+00 c:1.168e+01 Err: 8.198e+00 E:28 m:9.413e+00 c:1.168e+01 Err: 7.919e+00 E:29 m:9.427e+00 c:1.168e+01 Err: 7.717e+00 E:30 m:9.440e+00 c:1.168e+01 Err: 7.572e+00 E:31 m:9.450e+00 c:1.168e+01 Err: 7.467e+00 E:32 m:9.460e+00 c:1.168e+01 Err: 7.391e+00 E:33 m:9.467e+00 c:1.168e+01 Err: 7.336e+00 E:34 m:9.474e+00 c:1.168e+01 Err: 7.297e+00 E:35 m:9.479e+00 c:1.168e+01 Err: 7.269e+00 E:36 m:9.484e+00 c:1.168e+01 Err: 7.248e+00 E:37 m:9.488e+00 c:1.168e+01 Err: 7.233e+00 E:38 m:9.491e+00 c:1.168e+01 Err: 7.223e+00 E:39 m:9.494e+00 c:1.168e+01 Err: 7.215e+00 E:40 m:9.497e+00 c:1.168e+01 Err: 7.210e+00 E:41 m:9.499e+00 c:1.168e+01 Err: 7.206e+00 E:42 m:9.501e+00 c:1.168e+01 Err: 7.203e+00 E:43 m:9.502e+00 c:1.168e+01 Err: 7.201e+00 E:44 m:9.503e+00 c:1.168e+01 Err: 7.199e+00 E:45 m:9.504e+00 c:1.168e+01 Err: 7.198e+00 E:46 m:9.505e+00 c:1.168e+01 Err: 7.197e+00 E:47 m:9.506e+00 c:1.168e+01 Err: 7.197e+00 E:48 m:9.507e+00 c:1.168e+01 Err: 7.196e+00 E:49 m:9.507e+00 c:1.168e+01 Err: 7.196e+00 E:50 m:9.508e+00 c:1.168e+01 Err: 7.196e+00 E:51 m:9.508e+00 c:1.168e+01 Err: 7.196e+00 E:52 m:9.509e+00 c:1.168e+01 Err: 7.196e+00 E:53 m:9.509e+00 c:1.168e+01 Err: 7.195e+00 E:54 m:9.509e+00 c:1.168e+01 Err: 7.195e+00 E:55 m:9.509e+00 c:1.168e+01 Err: 7.195e+00 E:56 m:9.509e+00 c:1.168e+01 Err: 7.195e+00 E:57 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:58 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:59 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:60 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:61 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:62 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:63 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:64 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:65 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:66 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:67 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:68 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:69 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:70 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:71 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:72 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:73 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:74 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:75 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:76 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:77 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:78 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:79 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:80 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:81 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:82 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:83 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:84 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:85 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:86 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:87 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:88 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:89 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:90 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:91 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:92 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:93 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:94 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:95 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:96 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:97 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:98 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 E:99 m:9.510e+00 c:1.168e+01 Err: 7.195e+00 --- saving the gif (it can take some time, especially with many epoches) Please waiting... The gif has been successfully created!
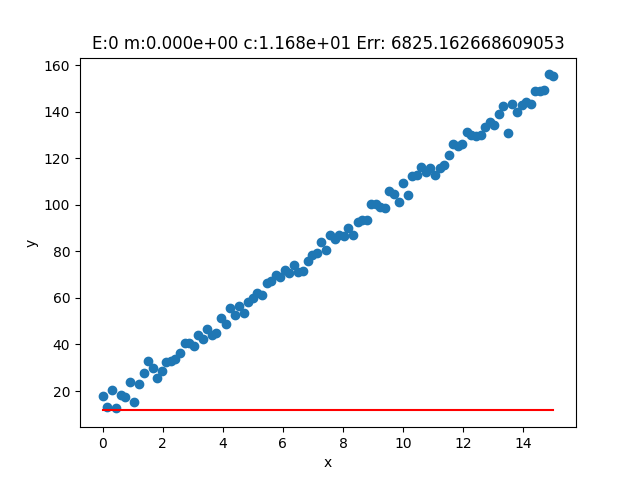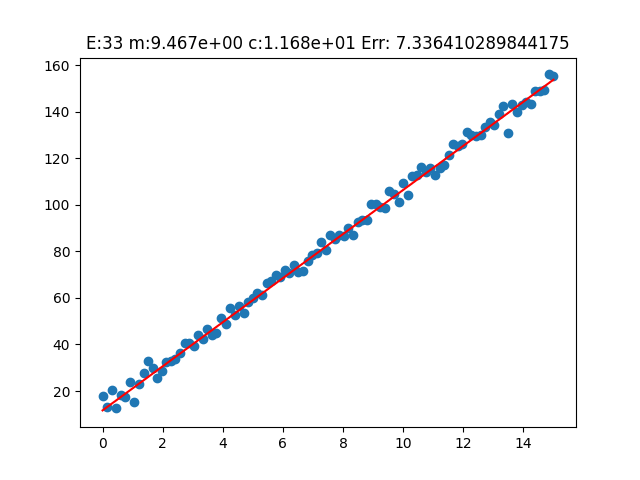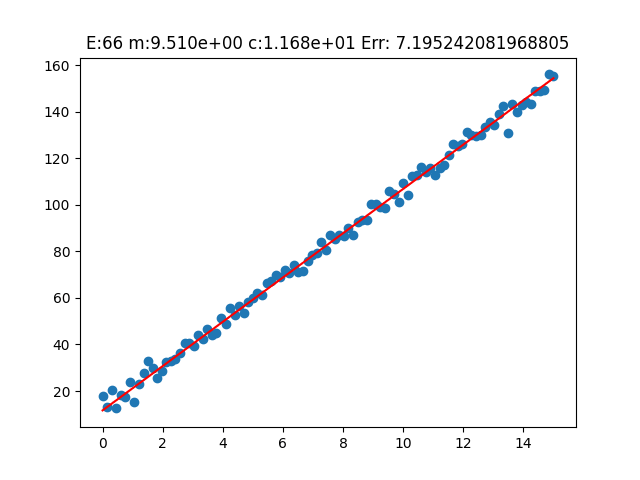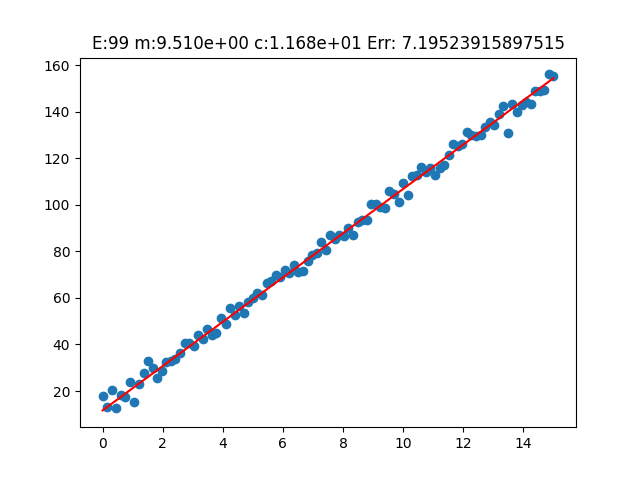
A questo punto, per valutare meglio l'andamento del modello in termini di diminuzione del valore della funzione di costo, plottiamo i valori della funzione di costo dopo ogni epoca
# Plot of error vs epoches
plt.plot(errors)
plt.xlabel("Epoches")
plt.ylabel("Error")
plt.title(f'Errors | Max Err {max(errors):.3e} | Min Err {min(errors):.3e}')
plt.tight_layout()
plt.show()
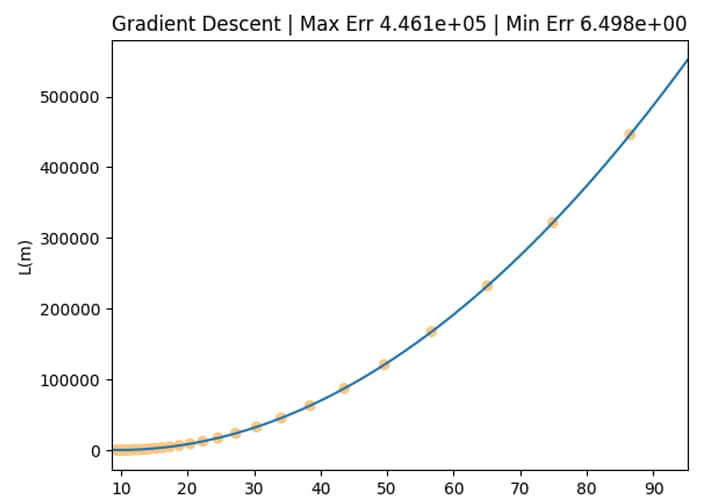
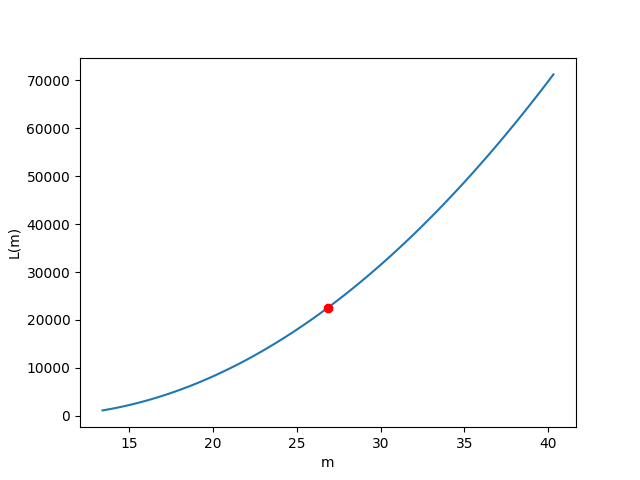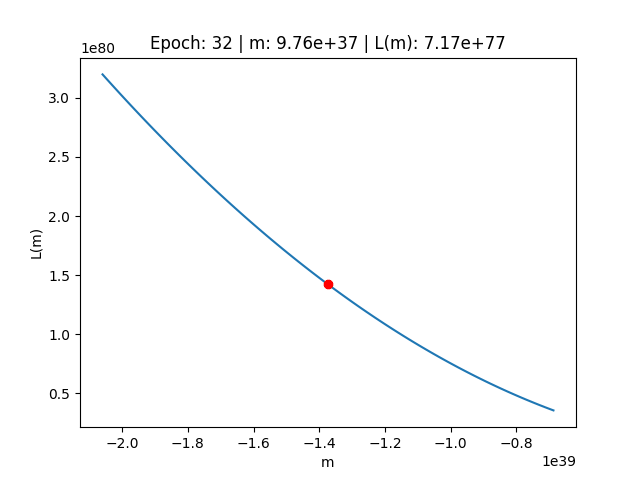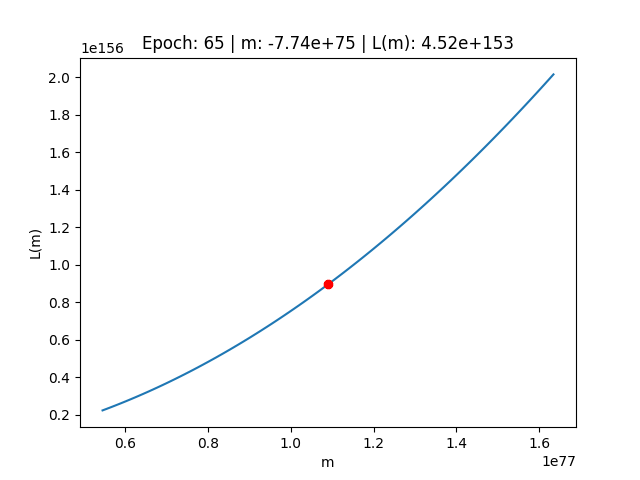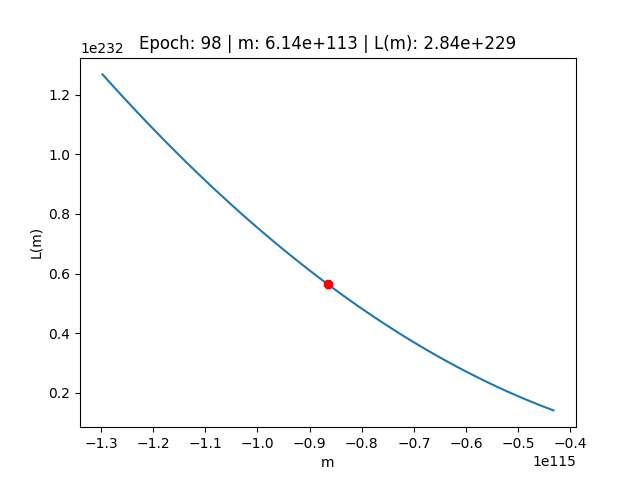
Visualizziamo l'andamento della funzione di costo L(m) al variare di m
Andiamo a creare un plot che ci mostra
- la funzione di costo $L(m)$ in un intervallo sull'asse orizzontale che va da max(m) a min(m)
- i valori di $L(m)$ assunti con il il variare del coefficiente angolare $m$ nelle varie epoche
Questo ci permetterà di avere una overview complessiva di come l'errore in ogni epoca si è mosso all'interno della funzione di errore. I tre casi principali sono:
- Comprotamento nomrale i valori assunti da $L(m)$ al variare di $m$ tendono a scendere verso il punto di minimo di $L(m)$
- Esplosione del gradiente i valori assunti da $L(m)$ al variare di $m$ vanno verso gli estremi di $L(m)$
- Scomparsa del gradiente i valori assunti da $L(m)$ al variare di $m$ si muovono in un intervallo $m$ molto ristretto e gli estremi min(m) e max(m) sono molto vicini tra loro
x_axis_min = min(M) - abs(min(M))*0.1
x_axis_max = max(M) + abs(max(M))*0.1
f_error_dict = {}
# Define the range of values for m
horiz = np.linspace(x_axis_min , x_axis_max, len(M) )
# Calculate the function values for each m value
f_error_values = [ f_error(n, elem, c, X, Y) for elem in horiz]
plt.xlim(x_axis_min, x_axis_max)
# Plot the function values
plt.plot(horiz, f_error_values)
# plot the scatter plot
plt.scatter(M, errors, c=cm.copper(M))
plt.xlabel('m')
plt.ylabel('L(m)')
plt.title(f'Gradient Descent | Max Err {max(errors):.3e} | Min Err {min(errors):.3e}')
plt.show()
Animiamo l'andamento della funzione di costo L(m) al variare di m
Andiamo a ricreare il plot di cui sopra che ci mostra in maniera animata tramite una gif, l'andamento dei valori di $L(m)$ assunti con il il variare del coefficiente angolare $m$ nelle varie epoche
Questo ci permetterà di avere una overview complessiva di come l'errore in ogni epoca si è mosso all'interno della funzione di errore. I tre casi principali sono:
- Comprotamento nomrale i valori assunti da $L(m)$ al variare di $m$ tendono a scendere verso il punto di minimo di $L(m)$
- Esplosione del gradiente i valori assunti da $L(m)$ al variare di $m$ tendono a saltare da una parte all'altra di $L(m)$
- Scomparsa del gradiente i valori assunti da $L(m)$ al variare di $m$ si muovono talmente lentamente su $L(m)$ da sembrare immobili
P.S.: dato che non avevo mai lavorato con le gif, parte di questo codice è stato fatto con l'ausilio di ChatGPT che ringuazio per il tempo che mi ha risparmiato su diverse cose di questo notebook 🙂
gif_filename = "gradient_approach.gif"
# Initialize figure
fig, ax = plt.subplots()
# Set axis labels and title
ax.set_xlabel('m')
ax.set_ylabel('L(m)')
# Initialize empty list for frames
frames = []
print('Starting creating the gif frames')
print('---')
# Create the scatter plot for each point
for i in range(len(M)):
# Clear the plot for the next iteration
ax.clear()
x_axis_min = M[i] - abs(M[i])*0.5
x_axis_max = M[i] + abs(M[i])*0.5
# Define the range of values for m
horiz = np.linspace(x_axis_min , x_axis_max, len(M) )
# Calculate the function values for each m value
f_error_values = [ f_error(n, elem, c, X, Y) for elem in horiz]
ax.plot(horiz, f_error_values, zorder=1)
# Create lists of x and y values for scatter plot
scatter_x = M[i]
scatter_y = errors[i]
# Plot the scatter plot
ax.scatter(scatter_x, scatter_y, zorder=2, color='red')
# Save the current plot as a PIL image
fig.canvas.draw()
frame = Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())
frames.append(frame)
# set the tick density on the X and Y axes
ax.locator_params(axis='x', nbins=10)
ax.locator_params(axis='y', nbins=10)
ax.set_xlabel('m')
ax.set_ylabel('L(m)')
ax.set_title(f'Epoch: {i} | m: {scatter_x:.2e} | L(m): {scatter_y:.2e}')
print(f'Epoch: {i} | m: {scatter_x:.2e} | L(m): {scatter_y:.2e}')
# Close the plot to avoid displaying it
plt.close()
print('---')
print('saving the gif (it can take some time, especially with many epoches)')
print('Please waiting...')
# Save the gif
frames[0].save(gif_filename, format='GIF', append_images=frames[1:], save_all=True, duration=300, loop=0)
print('The gif has been successfully created!')
HTML(f'To open it <a href="{gif_filename}" target="_blank"> click here</a>')
Esplosione del gradiente
Vediamo come si comporta durente durante il fenomeno dell'esplosione del gradiente quando utilizziamo un valore troppo alto per il Learning Rate.
Facciamo quindi un altro test, con una distribuzione simile alla precendete dove però andiamo ad utilizzare un valore "troppo alto" Learning Rate:
# Settiamo un valore troppo alto per il Learning rate
lr = 0.1A questo punto, procedendo di nuovo con l'algoritmo di discesa del gradiente come sopra, vediamo che otteniamo risultati completamente diversi
> real_slope (m): 9.540138588033479 > real_intercept (c): 11.68243651564374 --- > predicted_slope (m): 1.2171599361369272e+116 > known_intercept (c): 11.68243651564374 --- > Min Error: 22579.470928067338

E analizzando il comportamento dell'errore sulla funzione di costo, ci rendiamo conto di come l'errore non abbia fatto altro che rimbalzare da una parte all'altra della funzione di costo crescendo senza sosta
Starting creating the gif frames --- Epoch: 0 | m: 2.69e+01 | L(m): 2.26e+04 Epoch: 1 | m: -2.34e+02 | L(m): 4.47e+06 Epoch: 2 | m: 3.44e+03 | L(m): 8.86e+08 Epoch: 3 | m: -4.83e+04 | L(m): 1.76e+11 Epoch: 4 | m: 6.79e+05 | L(m): 3.48e+13 Epoch: 5 | m: -9.56e+06 | L(m): 6.89e+15 Epoch: 6 | m: 1.35e+08 | L(m): 1.37e+18 Epoch: 7 | m: -1.89e+09 | L(m): 2.71e+20 Epoch: 8 | m: 2.67e+10 | L(m): 5.36e+22 Epoch: 9 | m: -3.75e+11 | L(m): 1.06e+25 Epoch: 10 | m: 5.28e+12 | L(m): 2.10e+27 Epoch: 11 | m: -7.44e+13 | L(m): 4.17e+29 Epoch: 12 | m: 1.05e+15 | L(m): 8.26e+31 Epoch: 13 | m: -1.47e+16 | L(m): 1.64e+34 Epoch: 14 | m: 2.07e+17 | L(m): 3.24e+36 Epoch: 15 | m: -2.92e+18 | L(m): 6.42e+38 Epoch: 16 | m: 4.11e+19 | L(m): 1.27e+41 Epoch: 17 | m: -5.78e+20 | L(m): 2.52e+43 Epoch: 18 | m: 8.14e+21 | L(m): 5.00e+45 Epoch: 19 | m: -1.15e+23 | L(m): 9.90e+47 Epoch: 20 | m: 1.61e+24 | L(m): 1.96e+50 Epoch: 21 | m: -2.27e+25 | L(m): 3.89e+52 Epoch: 22 | m: 3.20e+26 | L(m): 7.70e+54 Epoch: 23 | m: -4.50e+27 | L(m): 1.53e+57 Epoch: 24 | m: 6.33e+28 | L(m): 3.02e+59 Epoch: 25 | m: -8.91e+29 | L(m): 5.99e+61 Epoch: 26 | m: 1.25e+31 | L(m): 1.19e+64 Epoch: 27 | m: -1.77e+32 | L(m): 2.35e+66 Epoch: 28 | m: 2.49e+33 | L(m): 4.66e+68 Epoch: 29 | m: -3.50e+34 | L(m): 9.22e+70 Epoch: 30 | m: 4.92e+35 | L(m): 1.83e+73 Epoch: 31 | m: -6.93e+36 | L(m): 3.62e+75 Epoch: 32 | m: 9.76e+37 | L(m): 7.17e+77 Epoch: 33 | m: -1.37e+39 | L(m): 1.42e+80 Epoch: 34 | m: 1.93e+40 | L(m): 2.82e+82 Epoch: 35 | m: -2.72e+41 | L(m): 5.58e+84 Epoch: 36 | m: 3.83e+42 | L(m): 1.11e+87 Epoch: 37 | m: -5.39e+43 | L(m): 2.19e+89 Epoch: 38 | m: 7.59e+44 | L(m): 4.34e+91 Epoch: 39 | m: -1.07e+46 | L(m): 8.60e+93 Epoch: 40 | m: 1.50e+47 | L(m): 1.70e+96 Epoch: 41 | m: -2.12e+48 | L(m): 3.38e+98 Epoch: 42 | m: 2.98e+49 | L(m): 6.69e+100 Epoch: 43 | m: -4.19e+50 | L(m): 1.32e+103 Epoch: 44 | m: 5.90e+51 | L(m): 2.62e+105 Epoch: 45 | m: -8.31e+52 | L(m): 5.20e+107 Epoch: 46 | m: 1.17e+54 | L(m): 1.03e+110 Epoch: 47 | m: -1.65e+55 | L(m): 2.04e+112 Epoch: 48 | m: 2.32e+56 | L(m): 4.04e+114 Epoch: 49 | m: -3.26e+57 | L(m): 8.01e+116 Epoch: 50 | m: 4.59e+58 | L(m): 1.59e+119 Epoch: 51 | m: -6.46e+59 | L(m): 3.15e+121 Epoch: 52 | m: 9.09e+60 | L(m): 6.23e+123 Epoch: 53 | m: -1.28e+62 | L(m): 1.23e+126 Epoch: 54 | m: 1.80e+63 | L(m): 2.45e+128 Epoch: 55 | m: -2.54e+64 | L(m): 4.85e+130 Epoch: 56 | m: 3.57e+65 | L(m): 9.60e+132 Epoch: 57 | m: -5.02e+66 | L(m): 1.90e+135 Epoch: 58 | m: 7.07e+67 | L(m): 3.77e+137 Epoch: 59 | m: -9.95e+68 | L(m): 7.47e+139 Epoch: 60 | m: 1.40e+70 | L(m): 1.48e+142 Epoch: 61 | m: -1.97e+71 | L(m): 2.93e+144 Epoch: 62 | m: 2.78e+72 | L(m): 5.81e+146 Epoch: 63 | m: -3.91e+73 | L(m): 1.15e+149 Epoch: 64 | m: 5.50e+74 | L(m): 2.28e+151 Epoch: 65 | m: -7.74e+75 | L(m): 4.52e+153 Epoch: 66 | m: 1.09e+77 | L(m): 8.95e+155 Epoch: 67 | m: -1.53e+78 | L(m): 1.77e+158 Epoch: 68 | m: 2.16e+79 | L(m): 3.51e+160 Epoch: 69 | m: -3.04e+80 | L(m): 6.96e+162 Epoch: 70 | m: 4.28e+81 | L(m): 1.38e+165 Epoch: 71 | m: -6.02e+82 | L(m): 2.73e+167 Epoch: 72 | m: 8.47e+83 | L(m): 5.41e+169 Epoch: 73 | m: -1.19e+85 | L(m): 1.07e+172 Epoch: 74 | m: 1.68e+86 | L(m): 2.13e+174 Epoch: 75 | m: -2.36e+87 | L(m): 4.21e+176 Epoch: 76 | m: 3.33e+88 | L(m): 8.34e+178 Epoch: 77 | m: -4.68e+89 | L(m): 1.65e+181 Epoch: 78 | m: 6.59e+90 | L(m): 3.27e+183 Epoch: 79 | m: -9.28e+91 | L(m): 6.49e+185 Epoch: 80 | m: 1.31e+93 | L(m): 1.29e+188 Epoch: 81 | m: -1.84e+94 | L(m): 2.55e+190 Epoch: 82 | m: 2.59e+95 | L(m): 5.05e+192 Epoch: 83 | m: -3.64e+96 | L(m): 1.00e+195 Epoch: 84 | m: 5.13e+97 | L(m): 1.98e+197 Epoch: 85 | m: -7.22e+98 | L(m): 3.92e+199 Epoch: 86 | m: 1.02e+100 | L(m): 7.78e+201 Epoch: 87 | m: -1.43e+101 | L(m): 1.54e+204 Epoch: 88 | m: 2.01e+102 | L(m): 3.05e+206 Epoch: 89 | m: -2.83e+103 | L(m): 6.05e+208 Epoch: 90 | m: 3.99e+104 | L(m): 1.20e+211 Epoch: 91 | m: -5.61e+105 | L(m): 2.37e+213 Epoch: 92 | m: 7.90e+106 | L(m): 4.70e+215 Epoch: 93 | m: -1.11e+108 | L(m): 9.32e+217 Epoch: 94 | m: 1.57e+109 | L(m): 1.85e+220 Epoch: 95 | m: -2.20e+110 | L(m): 3.66e+222 Epoch: 96 | m: 3.10e+111 | L(m): 7.25e+224 Epoch: 97 | m: -4.36e+112 | L(m): 1.44e+227 Epoch: 98 | m: 6.14e+113 | L(m): 2.84e+229 Epoch: 99 | m: -8.65e+114 | L(m): 5.64e+231 --- saving the gif (it can take some time, especially with many epoches) The gif has been successfully created!
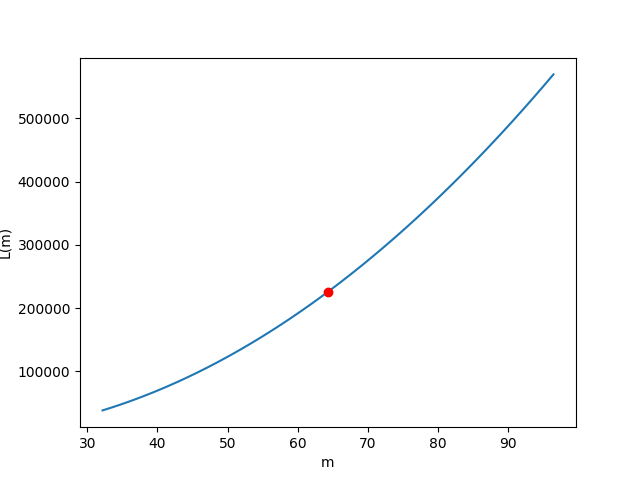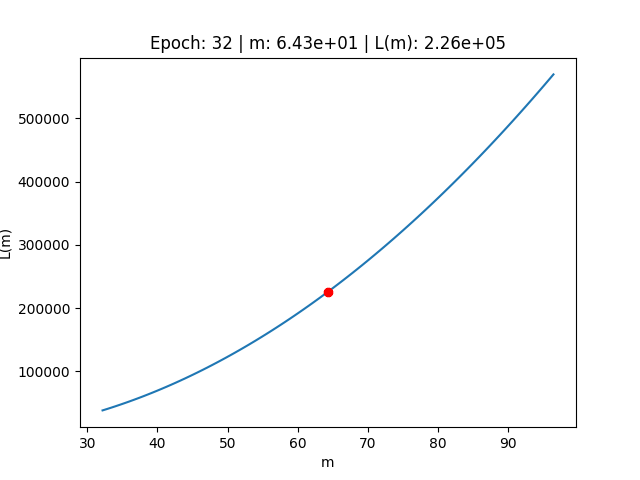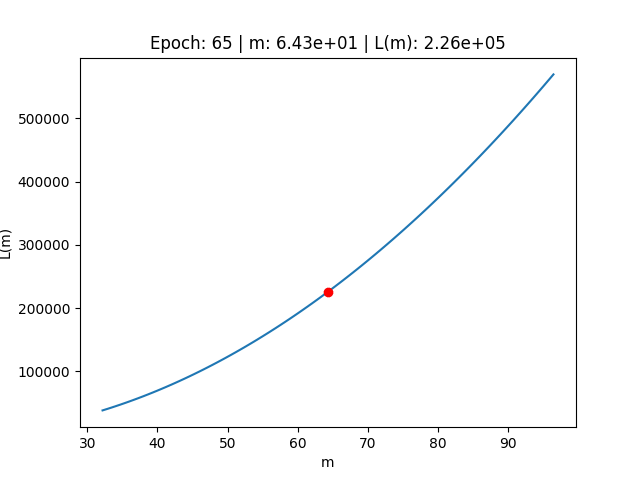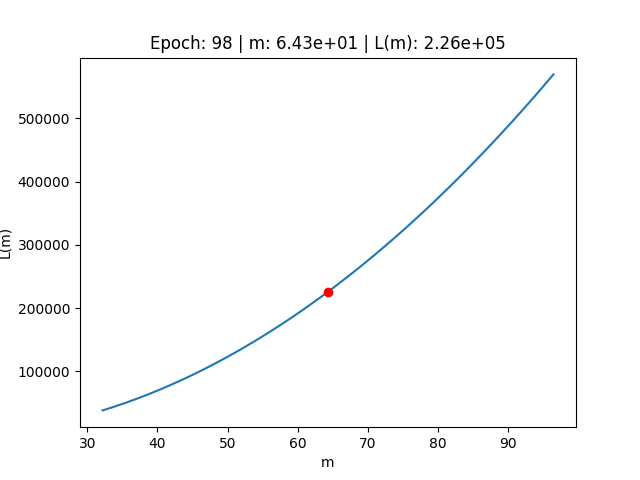
Scomprasa del gradiente
Al contrario, utilizzando un valore di Learning Rate troppo basso, possiamo osservare il fenomeno della scomparsa del gradiente.
In questo caso modifichiamo il valore del Learning Rate ad un valore "troppo basso"
# Settiamo un valore troppo basso per il Learning rate lr = 0.0000000001E anche in questo caso, procedendo con l'algoritmo di discesa del gradient, vediamo che otteniamo risultati completamente diversi.
> real_slope (m): 9.540138588033479 > real_intercept (c): 11.68243651564374 --- > predicted_slope (m): 64.32288127104336 > known_intercept (c): 11.68243651564374 --- > Min Error: 226045.08213663843

In questo caso, osservando il comportamento dell'errore sulla funzione di costo, ci rendiamo conto di come l'errore abbia fatto movimenti talmente infinitesimali sulla funzione di costo, da non essere stato in grado di aggiornare i parametri nel modo opportuno.
Starting creating the gif frames --- Epoch: 0 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 1 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 2 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 3 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 4 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 5 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 6 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 7 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 8 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 9 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 10 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 11 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 12 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 13 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 14 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 15 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 16 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 17 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 18 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 19 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 20 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 21 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 22 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 23 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 24 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 25 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 26 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 27 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 28 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 29 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 30 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 31 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 32 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 33 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 34 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 35 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 36 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 37 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 38 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 39 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 40 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 41 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 42 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 43 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 44 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 45 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 46 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 47 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 48 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 49 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 50 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 51 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 52 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 53 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 54 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 55 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 56 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 57 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 58 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 59 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 60 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 61 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 62 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 63 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 64 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 65 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 66 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 67 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 68 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 69 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 70 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 71 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 72 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 73 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 74 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 75 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 76 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 77 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 78 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 79 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 80 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 81 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 82 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 83 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 84 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 85 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 86 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 87 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 88 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 89 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 90 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 91 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 92 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 93 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 94 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 95 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 96 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 97 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 98 | m: 6.43e+01 | L(m): 2.26e+05 Epoch: 99 | m: 6.43e+01 | L(m): 2.26e+05 --- saving the gif (it can take some time, especially with many epoches) Please waiting... The gif has been successfully created!