Intoduction
- [01] Intoduction
This article on the latent space is inspired by a video I created for Data Masters.
Data Masters is an Italian AI Academy offering training programs in Data Science, Machine Learning, and Artificial Intelligence.
If you’d like more information about their courses and educational materials, visit datamasters.it.
At the end of this article, you’ll find the link to the original video.
Intuitive Introduction to the Concept of Latent Space
With this article, we begin a series dedicated to the concept of latent space, aiming to build a conceptual understanding, first intuitive, then increasingly technical and formal, of one of the fundamental ideas behind how neural networks work.
In this first part, we’ll focus on an intuitive, non-technical introduction to understand what the latent space is and what it represents inside a neural network.
In the following articles, we’ll see how this concept translates mathematically and geometrically, while keeping a conceptual and visual approach throughout.
What Is the Latent Space, in a Few Words?
We can think of the latent space as a transformed representation of the original data.
It’s a space where the initial data are “rewritten” in a form that allows the neural network to more easily understand and manipulate their fundamental features.
In other words: the network starts from raw data (images, text, audio, etc.) and translates them into an internal language, the latent space, where the most relevant information is emphasized and the irrelevant details are discarded.
This enables the model to extract, more efficiently, the information it needs to perform its task.
A First Example: Human Faces
Let’s imagine a dataset of face images.
In the input space, each image is represented as a grid of pixels: thousands of numbers describing the color and intensity of each point.
This representation is very detailed, but for a computer, it’s not very meaningful: it doesn’t describe concepts like “brown eyes” or “smile.”
The latent space, instead, can be thought of as a compact map of more abstract and meaningful features.
Conceptually (simplifying a lot), the image of a face might be represented by a few parameters such as hair color, age, gender, skin tone, expression, and so on.
This isn’t an explicit table, but rather an internal representation that captures the essence of the data, making them more useful to the model for its task, for example, facial recognition.
Let’s See It in Practice
Here, for instance, we have in our input space the visual image of a young man.
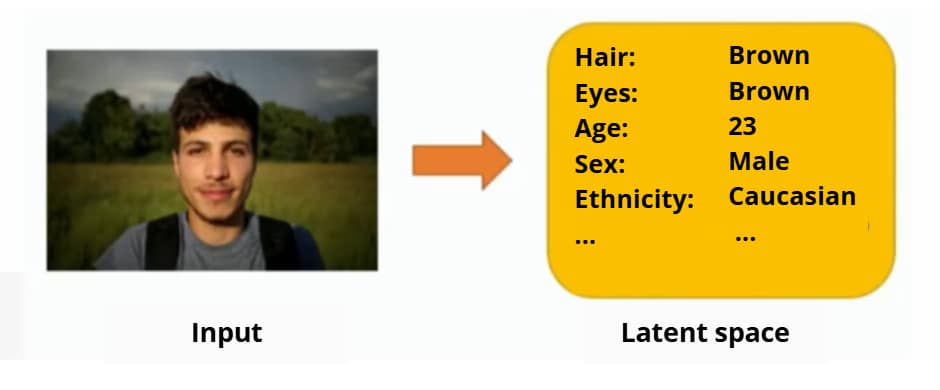
When we look at the image, we clearly perceive all the information we need. Our eyes capture and send to the brain all the relevant details.
Within the latent space, this specific image could, conceptually, be something like this: instead of storing the image itself, we have a set of values describing specific characteristics of that person.
For example:
- brown hair color
- brown eyes
- age 23
- male gender
- Caucasian ethnicity
This would be the “map” associated with that image. Other images would have maps with different characteristics.
So, when we look at a picture, our brain extracts all the information it needs, doing a kind of transformation similar to this process.
In the latent space, we can imagine all these images as being mapped somewhere.
Instead of thousands of pixels, their representation can be reduced to a few meaningful parameters like hair color, eye color, age, gender, ethnicity, and so forth.
We can thus imagine that these values together form our latent space.
It’s not exactly how it works in practice, but it’s a good conceptual approximation.
In this sense, the latent space is a space that transforms the input space, capturing its essence.
A Second Example: Satellite Images
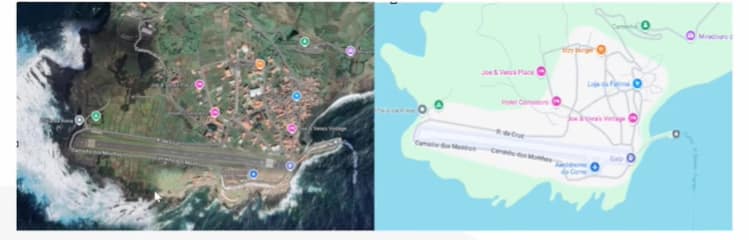
Now imagine working with satellite imagery.
In the input space, we see every detail: an airport runway, shadows, vegetation, roads, houses, and countless other elements.
So, in the input space, this map is represented with a huge amount of detail: every house, every road, the sea, even the ocean waves.
This representation is extremely information-rich and perfect for a human viewer, but redundant for a model that, for instance, needs to handle autonomous driving.
For such a task, many details (like the color of water or the density of vegetation) are irrelevant.
The latent space, in this case, could be seen as a simplified version of the map, similar to Google Maps’ “map” mode: only the essential information (roads, intersections, points of interest) is preserved, while everything else is removed.
However, if the task were different — say, assessing vegetation health — then the latent representation would need to highlight precisely those details that were discarded before.
This shows an important point:
The latent space is always relative to the task the network is trained for.
An Abstract and Useful Representation
Everything we’ve discussed so far is a highly simplified, intuitive, and conceptual way to start understanding what a latent space is.
In reality, a true latent space is an abstract mathematical space where the features learned by the model don’t necessarily correspond to human properties like “hair color” or “age.”
This also depends on the model and architecture being used.
In some cases, these features might represent coordinates in an n-dimensional space, or values describing probability distributions internal to the model.
What matters, in any case, is the core idea:
The latent space is a compressed and abstract representation of the data, useful for the model to perform its task.
What We’ll See in the Next Article about Latent Space
In the next chapter, we’ll enter the world of linear algebra, to understand how neural networks transform data from the input space into a latent space.
We’ll talk about transformation matrices, explore practical examples, and use tools like GeoGebra to visually and intuitively see how these transformations modify the entire data space.
You can find the original video here:
What Is the LATENT SPACE? A Conceptual Understanding – PART 1