
Elementi di Programmazione Classica
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
Pronti, via. Introduzione fatta e ora siamo pronti a partire per il nostro viaggio nella fondamenta dell'Intelligenza Artificiale.
E da dove si parte se non dalle basi?
In questa serie, abbiamo detto, si parla di Intelligenza Artificiale, ma prima di arrivare a parlare più nel dettaglio di Machine Learning, Reti Neurali, Deep Learning, etc, voglio fare un passo indietro, alle basi.
Sono fermamente convinto che delle solide fondamenta siano estremamente importanti quando si vuole costruire una conoscenza robusta e duratura nel tempo.
Non mi interessa infatti fornirti concetti fini a se stessi per riempire questi articoli. Il mio scopo è quello di farti ottenere la conoscenza necessaria affinché poi ti apparirà chiaro ciò di cui parleremo. Ovviamente, questo non è una serie per informatici, né tantomeno per matematici, quindi faremo tutto senza complicarci la vita con tecnicismi inutili.
Allo stesso tempo però, ti mostrerò la terminologia e i concetti chiave principali, che ti renderanno poi indipendente quando vorrai approfondire gli argomenti.
Cerchiamo quindi di capire qual è il confine che separa un programma dall'essere e dal non essere intelligente
Se vi sembra complesso, no worries, alla fine vi apparirà tutto chiaro.
Usando una terminologia un po' spartana, in questa serie divideremo l'Intelligenza Artificiale da un “programma classico”.
Diciamo quindi che possiamo definire un programma classico come una semplice sequenza di istruzioni che il computer si limita a eseguire e che, partendo da un punto A, lo porta a un punto B attraverso dei passi ben definiti.
Per aggiungere un po' di terminologia, con “programma classico” ci riferiremo a un computer che si limita a eseguire un algoritmo che contiene le informazioni esatte che il computer deve eseguire.
Il modo in cui il programmatore scrive questo programma nello specifico è poco rilevante.
Esistono centinaia (o migliaia) di linguaggi:
- Java
- Javascript
- C
- C++
- C#
- Python
- Scala
- Ruby
- PHP
- Visual Basic
- Julia
- etc etc
E altrettanti framework che specializzano questi linguaggi.
Ma il linguaggio specifico è solo un dettaglio e un linguaggio può essere preferito rispetto a un altro per un progetto specifico per tutta una serie di motivi tecnici o perché un certo linguaggio, per come è costituito, si presta meglio a un progetto piuttosto che a un altro.
Ma il vero cuore del nostro ragionamento è al di sopra del linguaggio.
Quello che davvero ci interessa è la sequenza di passaggi logici che ci permettono di partire dal problema, fino ad arrivare alla soluzione del problema stesso.
Il linguaggio specifico utilizzato, quindi, è solo una traduzione di quella serie di istruzioni in un insieme di codici che un computer è in grado di decodificare (attenzione, non di capire: una differenza molto importante).
E nel mondo reale funziona esattamente così.
Quando si sviluppa un software abbastanza strutturato infatti, non si inizia a scrivere di getto in un linguaggio di programmazione.
Prima di tutto, si lavora sulla logica che c'è dietro a quello che si vuole fare e solo dopo si traduce tutto nel linguaggio (o nei linguaggi) di programmazione scelto per quel determinato progetto.
Esistono infatti alcuni “meta-linguaggi” che sono utilizzati per definire prima di tutto la logica di ciò che si vuole ottenere, come ad esempio lo psudocodice.

Esistono addirittura dei linguaggi grafici come l’UML (Unified Modeling Language) oppure i diagrammi flowchart che permettono di progettare tutto visivamente utilizzando rettangoli, rombi, quadrati, linee, etc.
Esistono poi dei metodi di traduzione di questi meta-linguaggi ai linguaggi veri e propri, che permettono ai progettisti del software di partire da un disegno, sino ad arrivare a un codice che una macchina sarà in grado di decodificare.
Il cuore di tutto, quindi, sta proprio in questa logica concettuale che c'è dietro il programma stesso.
Ma questa logica chi la scrive? Il programmatore.
È il programmatore che fornisce chiare istruzioni alla macchina che, nella pratica, si limita a eseguirle.
Facciamo quindi un piccolo recap, alla luce di quanto abbiamo detto sinora.
Un programma classico (non “intelligente”), semplificando, non è altro che una sequenza di istruzioni logiche, che la macchina si limita a decodificare ed eseguire
Questa sequenza di istruzioni logiche, possiamo chiamarla algoritmo, ed è progettata da uno sviluppatore.
Un algoritmo è indipendente dal linguaggio di programmazione che sarà utilizzato, nello stesso identico modo in cui una storia è indipendente dalla lingua in cui verrà scritta.
Come una stessa storia può essere riscritta in più lingue rimanendo comunque invariata, così un algoritmo può essere tradotto in più linguaggi rimanendo comunque lo stesso.
Un po' di esempi
Ok, adesso siamo pronti a sporcarci un po' le mani, provando a buttare giù qualche algoritmo semplice semplice.
Esempio #1
PROBLEMA
Dato un numero maggiore di zero, stabilire se è pari o dispari.
SOLUZIONE
Per risolvere questo problema, utilizziamo una semplice proprietà dei numeri pari, per cui preso un qualunque numero pari e diviso per 2, il resto della divisione è sempre pari a zero.
L’operazione che estrae il resto da una divisione, sì indica con il simbolo % (e si legge 'resto')
Ad esempio 5 diviso 3 fa 1 con resto di 2, quindi 5%3 = 2 (5 resto 3 è uguale a 2)
Possiamo dunque schematizzare la soluzione al problema di qui sopra, attraverso il seguente algoritmo:
- Prendo il numero in ingresso, che definisco “n”
- Lo divido per 2
- Ne verifico il resto
- Se il resto è pari a zero, allora il numero è pari
- Altrimenti (se il resto è diverso da zero), allora in numero è dispari
- Restituisco il risultato (Pari, Dispari)

Facile no?
Proviamo ora con qualcosa che lavora sulle parole invece che sui numeri.
Esempio #2
PROBLEMA
Data una parola, restituire la parola riscritta al contrario (es. Roma > Amor)
NOTA: In informatichese, una sequenza di caratteri la definiamo stringa, quindi giusto per essere un po’ più precisi, in questo prossimo esempio non parleremo di ‘parola’ ma di ‘stringa’.
SOLUZIONE
- Prendo la stringa in ingresso
- Conto il numero di caratteri della stringa in ingresso
- Creo una nuova stringa vuota con lo stesso numero di caratteri della stringa in ingresso
- Mi posiziono all’ultima posizione della stringa in ingresso
- Mi posiziono alla prima posizione della nuova stringa
- Leggo il carattere della stringa in ingresso su cui sono posizionato e lo riporto uguale nella posizione della nuova stringa in cui sono posizionato
- Controllo se ci sono altri caratteri ancora da leggere nella stringa in ingresso (andando indietro)
- Se ci sono altri caratteri da leggere, mi sposto una posizione indietro nella stringa in ingresso e una posizione in avanti nella nuova stringa e torno al punto 6, altrimenti proseguo al punto 9
- Butto via la stringa in ingresso e restituisco in uscita la nuova stringa, che a questo punto conterrà proprio la stringa in ingresso rovesciata.
Dato che questo potrebbe sembrare un po’ macchinoso visto così, facciamo un piccolo esempio pratico prendendo la parola ROMA come stringa in ingresso.
Come prima cosa, prendiamo la stringa e contiamo il numero di caratteri ca cui è composta.
ROMA: 4 caratteriCreiamo quindi una nuova stringa composta da 4 caratteri, inizialmente vuoti.

Ci posizioniamo all’ultimo carattere stringa in ingresso, l’ultima A di ROMA, lo copiamo e lo incolliamo come primo carattere della nuova stringa creata che, a questo punto, sarà una stringa di 4 caratteri, di cui una prima A e 3 rimanenti posizioni vuote.
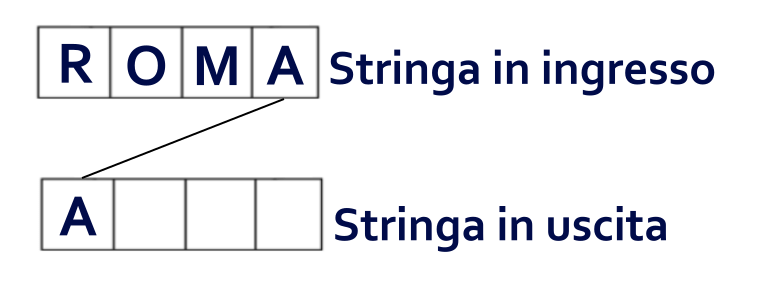
Ora controlliamo se la stringa in ingresso abbia altri caratteri andando indietro e, in questo caso, troviamo la M di ROMA.
Andiamo quindi una posizione indietro sulla stringa originale, posizionandoci quindi sulla M e andiamo una posizione avanti sulla stringa vuota. Come prima dunque, prendiamo la M, la copiamo e la incolliamo nella nuova stringa che, a questo punto, sarà composta da una A, una M e 2 restanti caratteri vuoti.
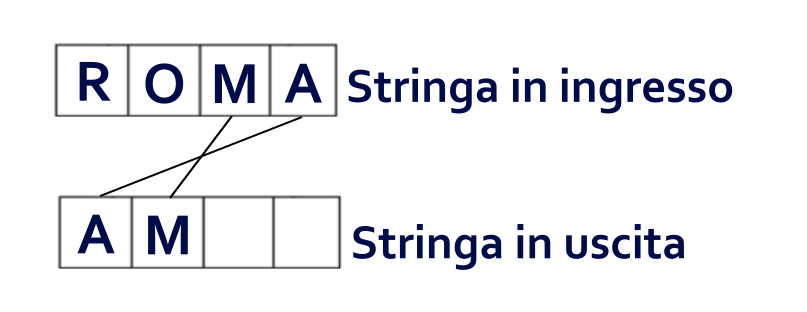
Facciamo lo stesso con la lettera O
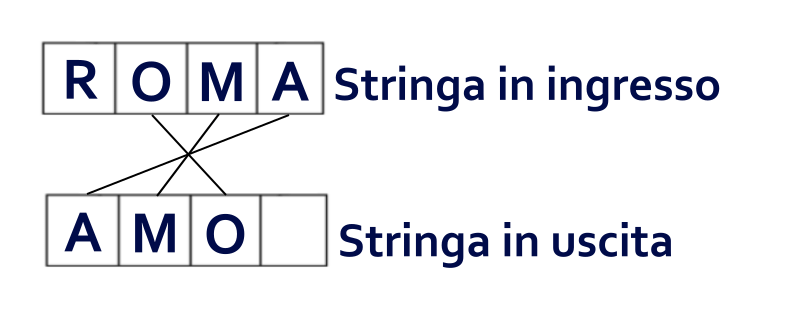
E concludiamo con l’ultimo carattere della stringa di partenza andando indietro: la R.
A questo punto infatti, dopo averlo incollato e aver verificato che non ci sono altri caratteri a disposizione, abbiamo finito.
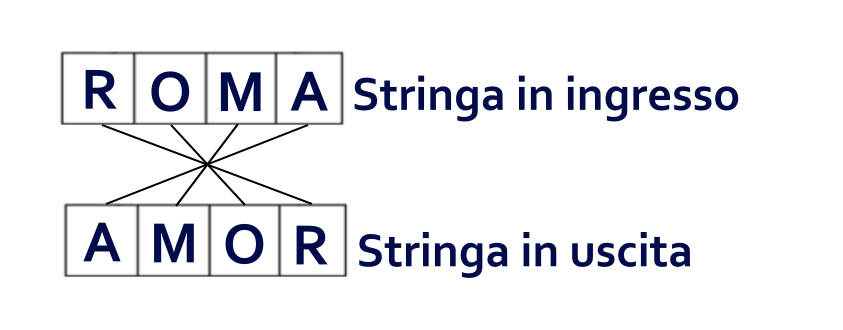
Scartiamo la stringa in ingresso e restituiamo in uscita la nuova stringa che, a questo punto, comporrà la parola AMOR.
Esempio #3
Ora vien da sé che, una volta definito questo algoritmo che data una parola ne restituisce la parola inversa, siamo anche in grado molto facilmente di realizzare un algoritmo che, data una parola ci può dire se è palindroma oppure no.
Lo definiamo così:
- Prendiamo la parola in ingresso
- Applichiamo l’algoritmo definito in precedenza e otteniamo una nuova stringa, che rappresenta la parola in ingresso invertita
- Confrontiamo la stringa originale con la stringa generata nel punto precedente
- Se le due stringhe sono uguali allora la parola in ingresso è palindroma, altrimenti non lo è
Bene, a questo punto ci è chiaro cos'è un algoritmo e che un programma classico non è altro che la traduzione di un algoritmo ben preciso in un linguaggio che la macchina è in grado di decodificare ed eseguire.
Limiti della “programmazione classica”
Ma ora è naturale chiedersi, fin dove siamo in grado di arrivare con la programmazione classica?
La risposta è che possiamo arrivare ovunque siamo in grado di arrivare a definire un algoritmo.
Ma un algoritmo, come abbiamo visto, non è altro che una serie di istruzioni ben precise definite che dicono esattamente alla macchina come risolvere il problema attraverso una sequenza logica esatta, quindi, con la programmazione classica, possiamo arrivare ovunque siamo in grado di arrivare attraverso la definizione di istruzioni ben precise.
E dunque, siamo in grado di arrivare fino a problemi tendenzialmente semplici per i quali possiamo definire un procedimento chiaro per la loro risoluzione.
E invece, per tutti quei problemi per cui invece non siamo in grado di definire un procedimento chiaro, come si fa?
Pensa ad esempio a questo problema: data un’immagine che sicuramente corrisponde all’immagine di un cane o di un gatto, definire se nell’immagine è presente un cane oppure un gatto.
In questo caso, sebbene il nostro cervello è in grado di risolvere questo problema in maniera estremamente semplice, noi in pratica non abbiamo realmente idea di cosa faccia per arrivare alla soluzione.
Sappiamo che si attivano aree del cervello addette a un compito piuttosto che a un altro, ma non siamo minimamente in grado di definire una serie di operazioni ben precise che a partire dall’immagine ci portano a dire se stiamo guardando un cane o un gatto.
Oppure, un altro problema che tendenzialmente sappiamo risolvere bene ma non abbiamo idea di come lo risolviamo nella pratica, può essere quello di stabilire se all’interno di uno specifico frammento di immagine c’è una strada libera (e quindi possiamo procedere) oppure un ostacolo (che invece dobbiamo evitare di prendere).
Potremmo quasi dire che il vero limite della programmazione classica, siamo noi stessi.
Con questo metodo, non possiamo arrivare oltre di ciò che siamo in grado di definire esattamente e chiaramente attraverso una serie di istruzioni ben precise.
Ma se ci pensiamo bene, i problemi che possiamo risolvere in questo modo, seppure siano moltissimi, sono limitati.
E tutto questo apre la strada a un gran numero di problemi che invece non siamo in grado di risolvere così e che spesso sono anche molto più interessanti.
Insomma, per andare oltre, abbiamo bisogno di qualcosa in più. Questo qualcosa in più è proprio quello che vedremo nei prossimi post della serie.







