
Reinforcement Learning
- [01] Introduzione
- [02] Elementi di Programmazione Classica
- [03] Tipologie di Intelligenza Artificiale
- [04] Elementi di Machine Learning
- [05] Apprendimento Supervisionato (Supervised Learning)
- [06] Apprendimento non Supervisionato (Unsupervised Learning)
- [07] Reinforcement Learning
- [08] Deep Learning e Neural Networks
- [09] Generative Models
Nei capitoli precedenti di questa serie, abbiamo parlato di Machine Learning e di come questa tecnologia si differenzi dalla programmazione classica.
Parlando di Machine Learning abbiamo fatto qualche esempio pratico e abbiamo visto come si svolge la fase di training, prendendo come esempio un modello di classificazione che avesse lo scopo di riconoscere immagini di cani da immagini di gatti.
Guardando la fase di training ci siamo resi conto di come questo processo sia simile a un processo di apprendimento umano.
Abbiamo visto infatti che il modello prova, sbaglia, impara, riprova e così via di epoca in epoca. Insomma, tentativi, errori, imparare dagli errori, nuovi tentativi.
Già di per sé, il fatto che questo sistema, totalmente compiuto da una macchina, sia simile al metodo di apprendimento umano è sorprendente. Eppure la parte più bella non è ancora arrivata. In questo capitolo infatti parliamo di Reinforcement Learning.
E iniziamo questo capitolo, con una citazione di Frank Rosenblatt, che conosceremo meglio in uno dei capitolo successivi, dedicato al Deep Learning e alle Reti Neurali (o Neural Networks).
Stiamo per assistere alla nascita di una macchina in grado di percepire, riconoscere e identificare l'ambiente circostante senza bisogno di nessun addestramento
- The Design of an Intelligent Automaton, Frank Rosenblatt
Come funziona?

Per farla semplice diciamo che il Reinforcement Learning è un'area del Machine Learning in cui quello che tecnicamente definiamo il nostro agente (che fa molto Matrix) impara direttamente attraverso l'interazione con l'ambiente circostante e tramite le conseguenze delle sue azioni.
Quindi, ricapitolando...
Abbiamo un agente, quest’agente interagisce con l'ambiente in cui si trova, le sue azioni hanno una conseguenza che può essere negativa o positiva e sulla base di questo, il nostro agente impara a relazionarsi con l'ambiente che lo circonda.
Benvenuto al mondo agente!
Insomma, il nostro agente percepisce l'ambiente che lo circonda attraverso quelli che potremmo definire i suoi sensi.
Sulla base di ciò che percepisce, agisce.
A questo punto registra, in quella che possiamo definire la sua memoria, le conseguenze che la sua azione ha generato e farà successivamente tesoro di questo insegnamento nelle sue prossime interazioni con il mondo esterno.
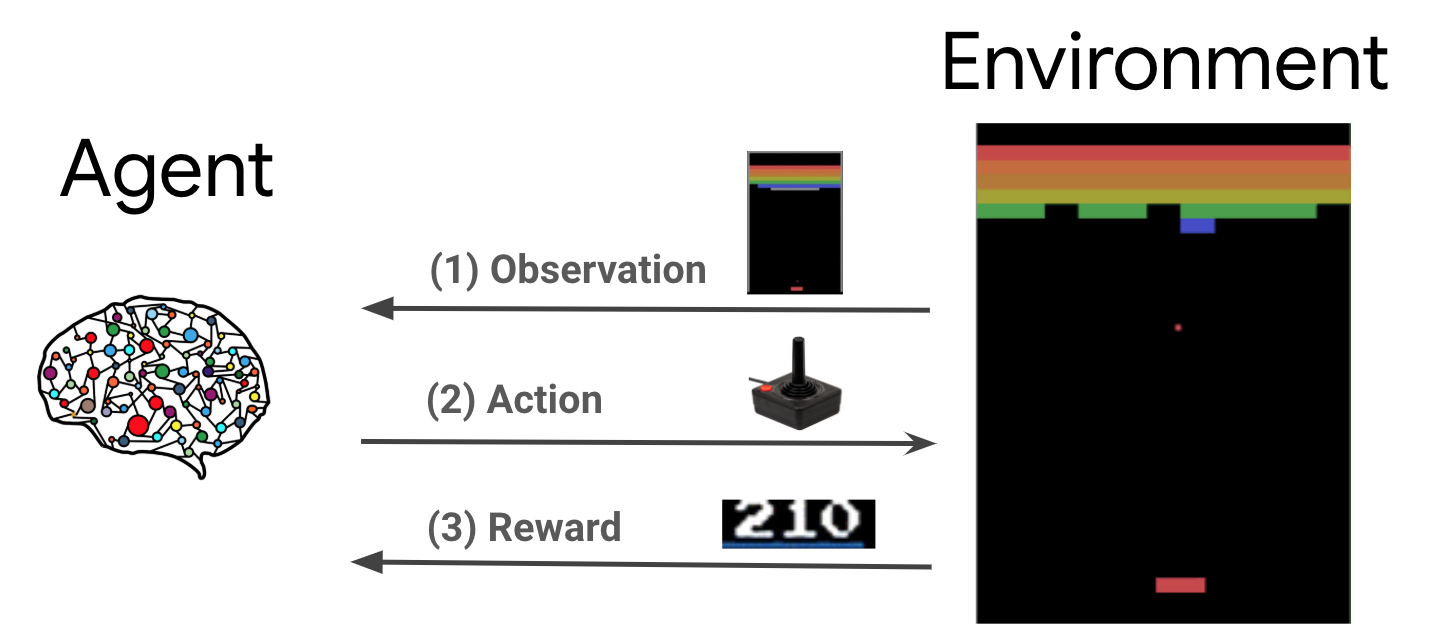
L'intero processo si basa su tre concetti:
- Interazione con l'ambiente esterno
- Premiare i comportamenti desiderati
- Penalizzare i comportamenti indesiderati
Questo potrebbe non sembrare troppo diverso da quello che accade con la classificazione. Anche in quel contesto infatti il modello impara dagli errori.
Ci sono però alcune differenze fondamentali, ma quella principale è che con la classificazione il modello apprende su dati forniti e costruiti ad hoc e solo successivamente lavora su dati generali, nel Reinforcement Learning invece, l'agente impara direttamente tramite l'interazione con l'ambiente, senza dati pre-impacchettati su cui imparare.
Lo scopo del classificatore infatti, è quello di imparare a generalizzare i dati imparando dagli errori sulle predizioni rispetto ai dati all'interno del dataset, individuando le caratteristiche generali che legano il problema alla soluzione, in modo tale poi da essere in grado di risolvere con buona affidabilità una qualunque istanza del problema.
In questo caso però, il nostro agente, non impara dai dati per poi arrivare a risolvere il problema in generale, ma impara direttamente mentre prova a risolvere il problema stesso.
Potremmo quasi dire che il nostro classificatore impara sui banchi di scuola, con dei dati appositamente preparati per farlo studiare e passare solo successivamente a lavorare su dati reali, mentre con il Reinforcement Learning il nostro agente impara dalla strada.
Nella versione più basilare del Reinforcement Learning, non ci sono dati che l’agente conosca già a priori. Tutto quello che impara, lo impara provando e osservando le conseguenze delle sue azioni.
In pratica agendo, l’agente impara e capisce la strada migliore per portare a termine il suo compito.
Vediamo qualche esempio pratico.
Pensiamo ad esempio a Super Mario, quello classico in due dimensioni, in cui bisogna stare attenti a tartarughe, piante carnivore, burroni e draghi sputa fuoco.
Lasciamo da parte le monete da dover prendere i fiori che donano super poteri e i funghetti che ci rendono grandi, seguiamo la piramide di Maslow e concentriamoci sulla sopravvivenza.
Definiamo un po' di cose innanzitutto.
Chi è l’agente? Super Mario che verrà controllato dalla nostra Intelligenza Artificiale.
Che cos'è l'ambiente circostante? Tutto quello che è intorno a Mario.
Quali sono le azioni che può compiere?
- Muoversi avanti
- Muoversi indietro
- Muoversi verso l'alto
- Muoversi verso il basso
- Saltare
Quali sono i comportamenti desiderati da premiare? Livello completato.
Quali sono i comportamenti indesiderati da scoraggiare? Mario muore.
Partiamo, mettiamo quindi il nostro agente nel mondo brutto e cattivo di Super Mario e vediamo cosa succede.
Notiamo che non abbiamo fornito nessun dato al nostro agente (Super Mario): dovrà fare tutto da solo utilizzando i feedback dell'ambiente esterno per capire se sta facendo bene o male.
All'inizio, probabilmente (non necessariamente), il nostro Mario farà la cosa più semplice: niente.
Se ne starà fermo, immobile a contemplare il panorama.
Poi però il tempo scadrà e Mario morirà.
Ma la sconfitta è uno dei comportamenti che vogliamo disincentivare e quindi, a questo punto, il nostro agente avrà imparato che stare fermo non funziona ai fini di ciò che vogliamo ottenere.
Nella prossima interazione, dunque, proverà qualcosa di diverso: magari resterà fermo e salterà sul posto (giusto per tenersi un po' in forma).
Ma anche qui, niente da fare, tempo scaduto e game over.
Piano piano, una prova alla volta, il nostro giovane Mario imparerà che non può starsene da solo in un angolo, ma che dovrà invece esplorare il mondo con coraggio.
Allora inizierà a muoversi. Forse ai suoi primi tentativi si limiterà a camminare diritto senza fare altro, ma come sa chiunque abbia mai giocato a Super Mario, questa non è una strategia funzionale e, poco dopo, morirà.
E così via, un tentativo alla volta il nostro agente, dopo un tempo relativamente lungo, avrà imparato a essere un campione assoluto in Super Mario.
Ricapitoliamo quindi…
Con il Reinforcement Learning, noi non insegniamo alla macchina quello che deve fare attraverso un dataset ben strutturato, ma piuttosto, mettiamo la macchina nel contesto reale e lasciamo che impari da sola.
Ora se ci pensiamo bene, questo è un ulteriore salto di paradigma.
Siamo partiti infatti dalla programmazione classica in cui dovevamo dire esattamente noi al computer quello che doveva fare attraverso una sequenza di istruzioni ben precise.
Siamo poi passati all'Apprendimento Supervisionato in cui noi non diciamo alla macchina quello che deve fare ma gli forniamo un insieme composto dal problema e dalla soluzione del problema per poi lasciare che si arrangi da sola a capire come risolvere.
Da lì siamo passati ad Apprendimento Non Supervisionato in cui non diamo più nemmeno le soluzioni alla macchina, ma ci limitiamo a fornirgli il problema e lasciare che capisca da sola la struttura sottostante.
Adesso siamo arrivati al Reinforcement Learning in cui non abbiamo più voglia nemmeno di dare il problema alla macchina, semplicemente ci limitiamo a:
- metterla all'interno dell'ambiente
- lasciare che interagisca con l'ambiente stesso
- darle feedback del risultato delle sue azioni (bene, male)
- lasciare che li provi di nuovo, alla luce di quanto hai imparato
In pratica lo scopo dell’agente è quello di andare verso il piacere (feedback positivo) e allontanarsi dal dolore (feedback negativo).
Esattamente come un cervello umano!
A noi spetta la responsabilità di dirgli cosa è giusto e cosa è sbagliato, proprio come fanno dei bravi genitori.
Certo abbiamo semplificato, ma a conti fatti e venendo al sodo, il Reinforcement Learning funziona esattamente così.
Mentre negli altri casi, addestriamo la nostra macchina, facendola imparare dai dati, nel Reinforcement Learning lasciamo che impari dall'esperienza, premiando i comportamenti che desideriamo e penalizzando invece quelli che vogliamo scoraggiare.
Piccola nota per i più tecnici, occhio che non stiamo parlando di una tecnica come quella del brute-force.
Cioè non stiamo parlando di un agente non intelligente che semplicemente prova tutte le possibili combinazioni fino a che, alla fine, dopo innumerevoli tentativi, trovi la combinazione corretta.
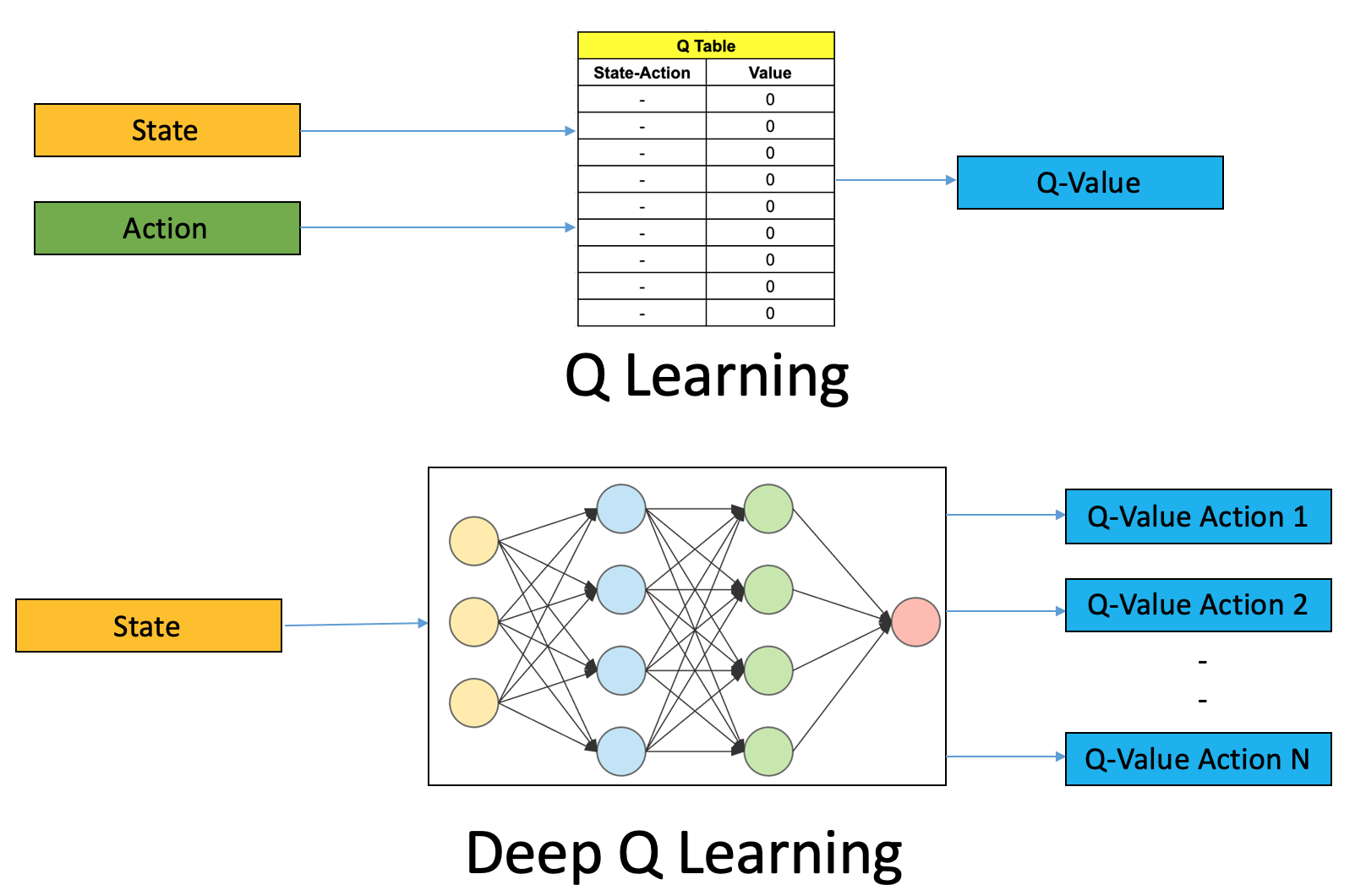
Le tecnica utilizzate con il Reinforcement Learning, sono di diverso tipo ma, allo stato attuale, tra le principali compare il Deep Q-Learning, estensione della più “antica” tecnica del Q-Learning, a cui viene associato il concetto di Deep Learning (che tratteremo nei prossimi capitili)
Date le sue caratteristiche, il Reinforcement Learning, è spesso utilizzato in contesti real time e in contesti in cui l’agente continua ad imparare durante il suo intero ciclo di vita, senza smettere mai. Ancora una volta, proprio come fa (o almeno dovrebbe fare) un essere umano.
Casi studio
Ci sono moltissimi casi studio che potete trovare sul web in cui si è messo l’agente all'interno di un contesto complesso e si è lasciato operare per capire che tipo di soluzione al problema avrebbe tirato fuori.
Sono stati fatti inoltre altri studi molto interessanti, in cui sono stati messi più agenti all'interno dello stesso ambiente per vedere come si sarebbe evoluto il rapporto tra questi agenti nel tempo, sia nei casi in cui si volevano favorire le collaborazioni, che nei casi in cui invece la vittoria di un agente avrebbe comportato la sconfitta di un altro (es. incontro di boxe tra agenti)
Sono stati fatti inoltre altri studi molto interessanti, in cui sono stati messi più agenti all'interno dello stesso ambiente per vedere come si sarebbe evoluto il rapporto tra questi agenti nel tempo, sia nei casi in cui si volevano favorire le collaborazioni, che nei casi in cui invece la vittoria di un agente avrebbe comportato la sconfitta di un altro (es. incontro di boxe tra agenti)
C’è inoltre un interessantissimo paper in cui OpenAI che ha fatto letteralmente giocare degli agenti a nascondino.
In pratica ha creato un ambiente in cui 4 agenti erano divisi in due squadre. Una squadra doveva nascondersi e non farsi trovare, mentre l'altra doveva cercarli.
Sono stati fatti esperimenti in diversi ambienti composte da mappe diverse tra loro e, in alcuni casi, sono venute fuori dinamiche estremamente interessanti.
Come ad esempio quando la squadra che doveva trovare l'altra, non riuscendo a trovarla per via di limiti fisici della mappa stessa che non gli permetteva l'accesso a una determinata area, tentando e ritentando, è riuscita a trovare un bug all'interno della mappa stessa e lo ha sfruttato per vincere la partita.
Interessante vero? Ma c'è un altro studio che mi ha davvero lasciato a bocca aperta e sono certo farà lo stesso effetto anche a te.
In questo studio sono stati costruiti fisicamente (non virtualmente) sei piccoli robottini composti da ruote, un motore per far girare le ruote, una striscia di luci a led che poteva assumere colori differenti e dei sensori per percepire il mondo intorno a loro.
Sei agenti controllavano questi sei piccoli robottini.
L'esperimento di base era semplice, ma quello che ne è venuto fuori e stato estremamente interessante.
In pratica, all'interno dell'ambiente di gioco, c'erano due differenti oggetti, posizionati in luoghi diversi.
Uno di questi oggetti rappresentava del cibo commestibile mentre l'altro rappresentava del cibo avvelenato.
Lo scopo dei nostri agenti era quello di mangiare cibo commestibile e non mangiare quello avvelenato entro un certo tempo (altrimenti sarebbero rimasti fermi come Super Mario al suo primo tentativo).
Quindi:
- comportamento positivo da premiare: mangiare cibo commestibile
- comportamento negativo da penalizzare: mangiare cibo avvelenato
Fino a qui è semplice, c'è però una condizione aggiuntiva all'esperimento che lo rende interessante.
Per superare il livello, infatti, era necessario che tutti i robottini mangiassero il cibo commestibile entro il tempo massimo.
In pratica l'esperimento era costruito in modo tale che per vincere, tutta la comunità di robottini avrebbe dovuto vincere.
Quindi, anche se ogni singolo robot fosse arrivato a raggiungere l'obiettivo (mangiare il cibo commestibile entro il tempo massimo) ma uno solo avesse fallito, tutti i robot avrebbero fallito e di conseguenza sarebbero stati penalizzati.
Dopo un certo numero di tentativi e fallimenti, è accaduto qualcosa che pare incredibile.
In pratica i robot hanno iniziato a rendersi conto che l'unico modo per vincere era cooperare in modo tale da mettere l'esperienza di ogni singolo robot a disposizione del gruppo.
In un tempo relativamente breve, i robot hanno capito che quella striscia di led che poteva cambiare colore non serviva solo per bellezza ma che, invece, poteva essere utilizzata per comunicare tra di loro. In pratica, i robot hanno sviluppato in maniera totalmente autonoma un sistema di comunicazione sfruttando i LED, senza che nessuno li avesse programmati per farlo.
Questo semplice esperimento ha provato come il concetto della comunicazione e della cooperazione, sia in grado di emergere anche in semplici reti neurali (nei prossimi capitoli approfondiremo questo termine)
Il Reinforcement Learning è stato anche utilizzato in alcuni esperimenti in cui degli agenti in diversi corpi (quadrupedi, bipedi, etc) hanno dovuto imparare da soli a utilizzare il loro corpo imparando a camminare senza cadere, a correre e a restare in piedi mentre gli venivano lanciati dei corpi esterni addosso per fargli perdere l’equilibrio.
Inoltre sono stati anche realizzati degli esperimenti in cui sì è insegnato a questi agenti a compiere vere e proprie acrobazie.
Utilità pratica
Se tutto questo è già rivoluzionario, diventa ancora più interessante se pensiamo a cosa possiamo ottenere con il Reinforcement Learning, se prima di tutto formiamo un agente all'interno di un mondo virtuale simulato, in cui possiamo creare noi in maniera veloce e a basso costo tutte le condizioni e gli eventi che vogliamo che l’agente impari ad affrontare, per poi trasferire questo agente in un robot nel mondo reale in modo che si porti dietro tutto ciò che hai imparato nelle fasi di simulazione.
Ad esempio, immaginiamo di voler costruire un robot in grado di fornire assistenza e prendersi carico di attività ad alto rischio in zone pericolose, come potrebbe essere la ricerca di sopravvissuti intrappolati in zone colpite da terremoto.
Non possiamo creare un robot guidato da un agente che deve ancora imparare tutto, perché non solo sarebbe troppo lento e inutile ai fini pratici, ma sarebbe anche pericoloso in un contesto reale.
Possiamo però addestrare l’agente in un contesto simulato in mondi virtuali, creando una sorta di "videogioco" in cui l’agente deve salvare delle vite.
In questo caso non solo saremmo in grado di addestrare il nostro agente in tempi rapidissimi, ma saremo anche in grado di farlo creando migliaia e migliaia di condizioni diverse in cui farlo operare.
Insomma, tanta roba!
E questo è ancora più incredibile se pensiamo che, nella pratica, siamo solo all'inizio di questa tecnologia.
Pensate ai progressi fatti dalla tecnologia solo negli ultimi 20 anni, è facile rendersi conto allora che stiamo vivendo un’era estremamente importante per lo sviluppo di questa tecnologia.
Bene, siamo arrivati alla conclusione di questo capitolo dedicato all'ultimo delle 3 categorie di Machine Learning: il Reinforcement Learning.
Nel prossimo capitolo proseguiremo il nostro viaggio nel Machine Learning andando ancora un po' più in profondità e parlando di Reti Neurali e Deep Learning.







